![]()

チュートリアル 1: ゲームのための強化学習
第3週5日目: ゲームプレイ学習と深層学習思考 3
Neuromatch Academy 提供
コンテンツ作成者: Mandana Samiei, Raymond Chua, Kushaan Gupta, Tim Lilicrap, Blake Richards
コンテンツレビュアー: Arush Tagade, Lily Cheng, Melvin Selim Atay, Kelson Shilling-Scrivo
コンテンツ編集者: Melvin Selim Atay, Spiros Chavlis, Gunnar Blohm
制作編集者: Namrata Bafna, Gagana B, Spiros Chavlis
チュートリアルの目的
このチュートリアルでは、ゲームループの実装方法、ランダムプレイヤーの作成方法、およびさまざまな強化学習手法を用いてプレイヤーの性能を向上させる方法を学びます。
このチュートリアルの具体的な目標:
- 2人対戦ゲームの形式、特にオセロを理解する
- ランダムプレイヤーの作り方を理解する
- 価値ベースのプレイヤーの実装方法を理解する
- 方策ベースのプレイヤーの実装方法を理解する
- モンテカルロプランナーを用いたプレイヤーの実装方法を理解する
# @title Tutorial slides
from IPython.display import IFrame
link_id = "3zn9w"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)セットアップ
# @title Install dependencies# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_dl",
"user_key": "f379rz8y",
},
).render()
feedback_prefix = "W3D5_T1"# Imports
import os
import time
import random
import logging
import coloredlogs
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
from tqdm.notebook import tqdm
from pickle import Unpickler
log = logging.getLogger(__name__)
coloredlogs.install(level='INFO') # Change this to DEBUG to see more info.# @title Helper functions
def loadTrainExamples(folder, filename):
"""
Helper function to load training examples
Args:
folder: string
Path specifying training examples
filename: string
File name of training examples
Returns:
trainExamplesHistory: list
Returns examples based on the model were already collected (loaded)
"""
trainExamplesHistory = []
modelFile = os.path.join(folder, filename)
examplesFile = modelFile + ".examples"
if not os.path.isfile(examplesFile):
print(f'File "{examplesFile}" with trainExamples not found!')
r = input("Continue? [y|n]")
if r != "y":
sys.exit()
else:
print("File with train examples found. Loading it...")
with open(examplesFile, "rb") as f:
trainExamplesHistory = Unpickler(f).load()
print('Loading done!')
return trainExamplesHistory
def save_model_checkpoint(folder, filename, nnet):
filepath = os.path.join(folder, filename)
if not os.path.exists(folder):
print(f"Checkpoint Directory does not exist! Making directory {folder}")
os.mkdir(folder)
else:
print("Checkpoint Directory exists!")
torch.save({'state_dict': nnet.state_dict()}, filepath)
print("Model saved!")
def load_model_checkpoint(folder, filename, nnet, device):
filepath = os.path.join(folder, filename)
if not os.path.exists(filepath):
raise FileNotFoundError(f"No model in path {filepath}")
checkpoint = torch.load(filepath, map_location=device)
nnet.load_state_dict(checkpoint['state_dict'])# @title Set random seed
# @markdown Executing `set_seed(seed=seed)` you are setting the seed
# For DL its critical to set the random seed so that students can have a
# baseline to compare their results to expected results.
# Read more here: https://pytorch.org/docs/stable/notes/randomness.html
# Call `set_seed` function in the exercises to ensure reproducibility.
def set_seed(seed=None, seed_torch=True):
"""
Function that controls randomness. NumPy and random modules must be imported.
Args:
seed : Integer
A non-negative integer that defines the random state. Default is `None`.
seed_torch : Boolean
If `True` sets the random seed for pytorch tensors, so pytorch module
must be imported. Default is `True`.
Returns:
Nothing.
"""
if seed is None:
seed = np.random.choice(2 ** 32)
random.seed(seed)
np.random.seed(seed)
if seed_torch:
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
print(f'Random seed {seed} has been set.')
# In case that `DataLoader` is used
def seed_worker(worker_id):
"""
DataLoader will reseed workers following randomness in
multi-process data loading algorithm.
Args:
worker_id: integer
ID of subprocess to seed. 0 means that
the data will be loaded in the main process
Refer: https://pytorch.org/docs/stable/data.html#data-loading-randomness for more details
Returns:
Nothing
"""
worker_seed = torch.initial_seed() % 2**32
np.random.seed(worker_seed)
random.seed(worker_seed)# @title Set device (GPU or CPU). Execute `set_device()`
# especially if torch modules used.
# Inform the user if the notebook uses GPU or CPU.
def set_device():
"""
Set the device. CUDA if available, CPU otherwise
Args:
None
Returns:
Nothing
"""
device = "cuda" if torch.cuda.is_available() else "cpu"
if device != "cuda":
print("WARNING: For this notebook to perform best, "
"if possible, in the menu under `Runtime` -> "
"`Change runtime type.` select `GPU` ")
else:
print("GPU is enabled in this notebook. \n"
"If you want to disable it, in the menu under `Runtime` -> \n"
"`Hardware accelerator.` and select `None` from the dropdown menu")
return deviceSEED = 2023
set_seed(seed=SEED)
DEVICE = set_device()# @title Download the modules
# @markdown Run this cell!
# @markdown Download from OSF. The original repo is https://github.com/raymondchua/nma_rl_games.git
import os, io, sys, shutil, zipfile
from urllib.request import urlopen
# download from github repo directly
#!git clone git://github.com/raymondchua/nma_rl_games.git --quiet
REPO_PATH = 'nma_rl_games'
if not os.path.exists(REPO_PATH):
download_string = "Downloading"
zipurl = 'https://osf.io/kf4p9/download'
print(f"{download_string} and unzipping the file... Please wait.")
with urlopen(zipurl) as zipresp:
with zipfile.ZipFile(io.BytesIO(zipresp.read())) as zfile:
zfile.extractall()
print("Download completed.")
# add the repo in the path
sys.path.append('nma_rl_games/alpha-zero')
print(f"Added the {REPO_PATH} in the path and imported the modules.")
# @markdown Import modules designed for use in this notebook
import Arena
from utils import *
from Game import Game
from MCTS import MCTS
from NeuralNet import NeuralNet
# from othello.OthelloPlayers import *
from othello.OthelloLogic import Board
# from othello.OthelloGame import OthelloGame
from othello.pytorch.NNet import NNetWrapper as NNetノートブック全体で使用するハイパーパラメータです。
args = dotdict({
'numIters': 1, # In training, number of iterations = 1000 and num of episodes = 100
'numEps': 1, # Number of complete self-play games to simulate during a new iteration.
'tempThreshold': 15, # To control exploration and exploitation
'updateThreshold': 0.6, # During arena playoff, new neural net will be accepted if threshold or more of games are won.
'maxlenOfQueue': 200, # Number of game examples to train the neural networks.
'numMCTSSims': 15, # Number of games moves for MCTS to simulate.
'arenaCompare': 10, # Number of games to play during arena play to determine if new net will be accepted.
'cpuct': 1,
'maxDepth': 5, # Maximum number of rollouts
'numMCsims': 5, # Number of monte carlo simulations
'mc_topk': 3, # Top k actions for monte carlo rollout
'checkpoint': './temp/',
'load_model': False,
'load_folder_file': ('/dev/models/8x100x50','best.pth.tar'),
'numItersForTrainExamplesHistory': 20,
# Define neural network arguments
'lr': 0.001, # lr: Learning Rate
'dropout': 0.3,
'epochs': 10,
'batch_size': 64,
'device': DEVICE,
'num_channels': 512,
})セクション 0: はじめに
# @title Video 0: Introduction
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', '5kQ-xGbjlJo'), ('Bilibili', 'BV1kq4y1H7MQ')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Introduction_Video")セクション 1: 強化学習のためのゲーム/エージェントループの作成
所要時間の目安: 約15分
# @title Video 1: A game loop for RL
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'aH2Hs8f6KrQ'), ('Bilibili', 'BV1iw411979L')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_A_game_loop_for_RL_Video")セクション 1.1: OthelloGame の紹介
オセロは、8×8のグリッドに配置された64マスの盤上で、2人のプレイヤーが対戦するボードゲームです。64個の駒は片面が黒、もう片面が白になっています。
セットアップ:
盤の中央に黒の駒2枚と白の駒2枚が配置されます。黒は北東から南西方向に、白は北西から南東方向に並びます。各プレイヤーは32枚の駒を持ち、黒が先手でゲームを開始します。
ゲームルール:
- プレイヤーは交互に1枚ずつ駒を置きます。
- 駒を置く際は、自分の色の駒で相手の駒を挟む(いわゆる「挟み打ち」)ように置きます。つまり、黒のプレイヤーは、新たに置く駒と既に盤上にある黒の駒の間に、1枚以上の白の駒が直線上に挟まれるように置かなければなりません。
- 挟まれた駒は裏返されて色が変わります。
- 有効な手がない場合はパスします。
- プレイヤーは自発的に手番を放棄することはできません。
- 両者とも有効な手がなくなった時点でゲーム終了です。
興味があれば、https://www.eothello.com/ のサイトで役立つルールや図を参照できます。また、サイト上でサンプルのオセロゲームをプレイすることも可能です。
注意: 計算を高速化するために、ここでは6×6の盤を使用します。
目標: 強化学習実験のために複数プレイヤーが参加するゲーム環境を構築する。
演習:
- ランダムに手を打つエージェントを作成する
- エージェント同士で対戦させて勝敗を計算する
以下のコードを実行すると、OthelloGame クラスが有効になります。このクラスはゲーム盤を表し、初期盤面を作成する getInitBoard メソッド、有効な手の選択肢を返す getValidMoves メソッドなど、ゲームをプレイするための便利な機能を備えています。このチュートリアルのすべてのコードを完全に理解する必要はありませんが、各メソッドの直感的な理解を目指してください。
class OthelloGame(Game):
"""
Othello game board
"""
square_content = {
-1: "X",
+0: "-",
+1: "O"
}
@staticmethod
def getSquarePiece(piece):
return OthelloGame.square_content[piece]
def __init__(self, n):
self.n = n
def getInitBoard(self):
b = Board(self.n)
return np.array(b.pieces)
def getBoardSize(self):
return (self.n, self.n)
def getActionSize(self):
# Return number of actions, n is the board size and +1 is for no-op action
return self.n * self.n + 1
def getCanonicalForm(self, board, player):
# Return state if player==1, else return -state if player==-1
return player * board
def stringRepresentation(self, board):
return board.tobytes()
def stringRepresentationReadable(self, board):
board_s = "".join(self.square_content[square] for row in board for square in row)
return board_s
def getScore(self, board, player):
b = Board(self.n)
b.pieces = np.copy(board)
return b.countDiff(player)
@staticmethod
def display(board):
n = board.shape[0]
print(" ", end="")
for y in range(n):
print(y, end=" ")
print("")
print("-----------------------")
for y in range(n):
print(y, "|", end="") # Print the row
for x in range(n):
piece = board[y][x] # Get the piece to print
print(OthelloGame.square_content[piece], end=" ")
print("|")
print("-----------------------")
@staticmethod
def displayValidMoves(moves):
A=np.reshape(moves[0:-1], board.shape)
n = board.shape[0]
print(" ")
print("possible moves")
print(" ", end="")
for y in range(n):
print(y, end=" ")
print("")
print("-----------------------")
for y in range(n):
print(y, "|", end="") # Print the row
for x in range(n):
piece = A[y][x] # Get the piece to print
print(OthelloGame.square_content[piece], end=" ")
print("|")
print("-----------------------")
def getNextState(self, board, player, action):
"""
Make valid move. If player takes action on board, return next (board,player)
and action must be a valid move
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
player: Integer
ID of current player
action: np.ndarray
Space of actions
Returns:
(board, player): tuple
Next state representation
"""
if action == self.n*self.n:
return (board, -player)
b = Board(self.n)
b.pieces = np.copy(board)
move = (int(action/self.n), action%self.n)
b.execute_move(move, player)
return (b.pieces, -player)
def getValidMoves(self, board, player):
"""
Get all valid moves for player
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
player: Integer
ID of current player
action: np.ndarray
Space of action
Returns:
valids: np.ndarray
Valid moves for player
"""
valids = [0]*self.getActionSize()
b = Board(self.n)
b.pieces = np.copy(board)
legalMoves = b.get_legal_moves(player)
if len(legalMoves)==0:
valids[-1]=1
return np.array(valids)
for x, y in legalMoves:
valids[self.n*x+y]=1
return np.array(valids)
def getGameEnded(self, board, player):
"""
Check if game ended
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
player: Integer
ID of current player
Returns:
0 if not ended, 1 if player 1 won, -1 if player 1 lost
"""
b = Board(self.n)
b.pieces = np.copy(board)
if b.has_legal_moves(player):
return 0
if b.has_legal_moves(-player):
return 0
if b.countDiff(player) > 0:
return 1
return -1
def getSymmetries(self, board, pi):
"""
Get mirror/rotational configurations of board
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
pi: np.ndarray
Dimension of board
Returns:
l: list
90 degree of board, 90 degree of pi_board
"""
assert(len(pi) == self.n**2+1) # 1 for pass
pi_board = np.reshape(pi[:-1], (self.n, self.n))
l = []
for i in range(1, 5):
for j in [True, False]:
newB = np.rot90(board, i)
newPi = np.rot90(pi_board, i)
if j:
newB = np.fliplr(newB)
newPi = np.fliplr(newPi)
l += [(newB, list(newPi.ravel()) + [pi[-1]])]
return l以下では、盤面を初期化して表示します。
# Set up the game
game = OthelloGame(6)
# Get the initial board
board = game.getInitBoard()
# Display the board
game.display(board)
# Observe the game board size
print(f'Board size = {game.getBoardSize()}')
# Observe the action size
print(f'Action size = {game.getActionSize()}')次に、プレイヤー1(丸)の有効な行動を見て、上記の盤面と比較します。
# Get valid moves
valids = game.getValidMoves(board, 1)
print(valids)
# Visualize the moves
game.displayValidMoves(valids)game.getValidMoves は盤上のすべての位置に対して1または0を返します。1は新しいディスクを置くことができる有効な場所を示します。これはリストとして返されます(盤面の形に変形することも可能です)。
また、盤上で有効な行動を視覚化するメソッドも用意しています。
セクション 1.2: ランダムプレイヤーの作成
まずはランダムプレイヤーを使ってゲームループを設定し、ゲームループが正しく動作するかテストしましょう。
そのために、ランダムプレイヤーを3つのステップで実装します:
- どの手が可能かを判定する
- 各手に一様な確率を割り当てる(ランダムプレイヤーなので):有効な手がN個なら1/N
- 可能な手の中からランダムに1つ選ぶ
コーディング演習 1.2: ランダムプレイヤーの実装
class RandomPlayer():
def __init__(self, game):
self.game = game
def play(self, board):
"""
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
Returns:
a: int
Randomly chosen move
"""
#################################################
## TODO for students: ##
## 1. Please compute the valid moves using getValidMoves() and the game class self.game. ##
## 2. Compute the probability over actions.##
## 3. Pick a random action based on the probability computed above.##
# Fill out function and remove ##
raise NotImplementedError("Implement the random player")
#################################################
# Compute the valid moves using getValidMoves()
valids = ...
# Compute the probability of each move being played (random player means
# this should be uniform for valid moves, 0 for others)
prob = ...
# Pick a random action based on the probabilities (hint: np.choice is useful)
a = ...
return a# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_a_Random_Player_Excercise")セクション 1.3: ランダムエージェント同士の対戦
ここでは2人のランダムプレイヤーを作成し、複数回対戦させます... 上でインポートした便利な機能の一つである Arena クラスを使います。複数回のゲームプレイを管理できます。コードを確認したい場合はこちらを参照してください(必須ではありません):https://github.com/raymondchua/nma_rl_games
# Define the random players
player1 = RandomPlayer(game).play # note the .play here to pass a function to Arena!
player2 = RandomPlayer(game).play
# Define number of games
num_games = 20
# Start the competition
set_seed(seed=SEED)
arena = Arena.Arena(player1, player2, game, display=None) # To see the steps of the competition set "display=OthelloGame.display"
result = arena.playGames(num_games, verbose=False) # returns (Number of player1 wins, number of player2 wins, number of ties)
# Compute win rate for the random player (player 1)
print(f"\nNumber of games won by player1 = {result[0]}, "
f"Number of games won by player2 = {result[1]} out of {num_games} games")
win_rate_player1 = result[0]/num_games
print(f"\nWin rate for player1 over 20 games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 13、プレイヤー2の勝利数 = 7(全20ゲーム中)
20ゲームにおけるプレイヤー1の勝率: 65.0%
注意: ランダムプレイヤーは純粋に方策ベースです。価値の推定は含まれていません。次に、ゲームプレイのために価値関数を推定し利用する方法を見ていきます。
セクション2: エキスパートのゲームデータから価値関数を学習する
所要時間の目安: 約35分
ゲームのセットアップと動作が完了したので、エキスパートのゲームデータを使って価値関数を学習し、(できれば)より賢いプレイヤーを作成しましょう。プレイヤーはこの価値関数を使ってどの手を打つか決定します。
目標: エキスパートがプレイしたゲームのデータセットから価値関数を学習する方法を理解する。
演習:
- エキスパートが生成したゲームのデータセットを読み込む。
- ゲーム中にサンプリングされた盤面状態に対して勝敗予測の平均二乗誤差(MSE)を最小化するようにネットワークを訓練する。これは非常に少数のゲームで行う。より大きなデータセットで訓練したネットワークは提供する。
- 価値関数を使ってランダムプレイヤーよりも強いプレイヤーを作る方法を学ぶ。
# @title Video 2: Train a value function
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'f9lZq0WQJFg'), ('Bilibili', 'BV1jf4y157xQ')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Train_a_Value_Function_Video")セクション2.1: エキスパートデータの読み込み
path = "nma_rl_games/alpha-zero/pretrained_models/data/"
loaded_games = loadTrainExamples(folder=path, filename='checkpoint_1.pth.tar')セクション2.2: オセロ用ニューラルネットワークのアーキテクチャ定義
ここでは(やや恣意的に)4層の畳み込み層と4層の線形層を持ち、ReLU活性化関数とバッチ正規化を用いた深層CNNを使います。畳み込みが興味深い理由の一つは、盤面の位置に依存せず局所的な手の価値を抽出できるため、畳み込みはプレイの平行移動不変な特徴を抽出できる点にあります。
Value Networkでは、3番目の線形層が方策(ポリシー)を表し、4番目の線形層(出力)が価値関数を表します。価値関数はすべての方策の重み付き和です。
これは、線形層3と4の間の重みが価値-行動関数 を近似していると仮定することで実現できます:
注意: OthelloNet は2つの出力を持ちます:
- 線形層3のlog-softmax
- 線形層4のtanh
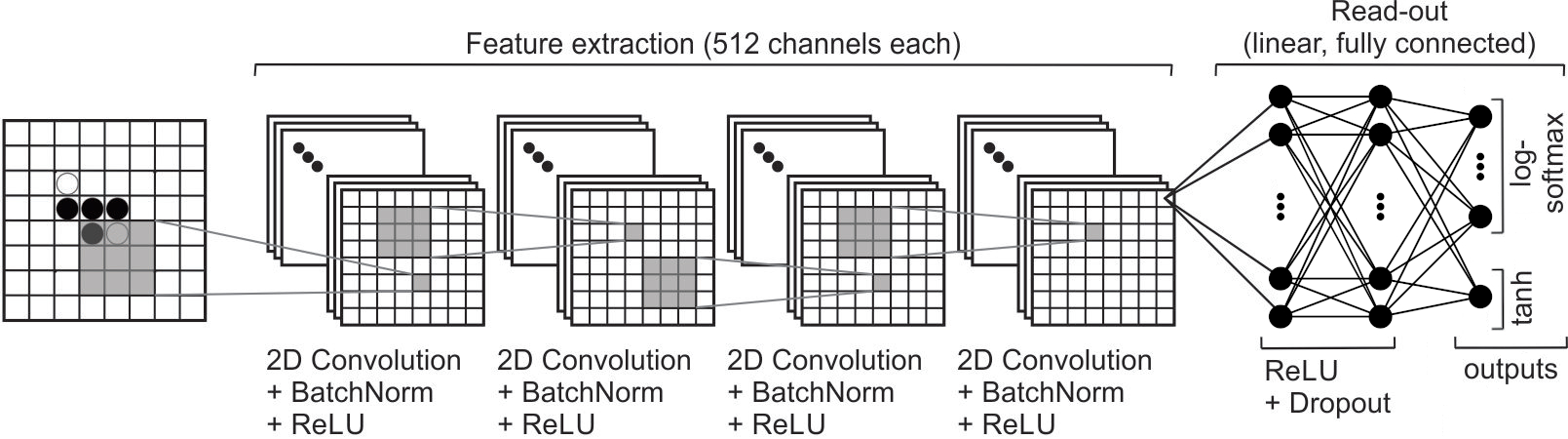
コーディング演習 2.2: オセロをプレイするための OthelloNNet を実装する
以下に OthelloNNet のほとんどを実装していますが、最終的な出力を得るためにコードを完成させてください。
class OthelloNNet(nn.Module):
def __init__(self, game, args):
"""
Initialise game parameters
Args:
game: OthelloGame instance
Instance of the OthelloGame class above;
args: dictionary
Instantiates number of iterations and episodes, controls temperature threshold, queue length,
arena, checkpointing, and neural network parameters:
learning-rate: 0.001, dropout: 0.3, epochs: 10, batch_size: 64,
num_channels: 512
"""
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.args = args
super(OthelloNNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=args.num_channels,
kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=args.num_channels,
out_channels=args.num_channels, kernel_size=3,
stride=1, padding=1)
self.conv3 = nn.Conv2d(in_channels=args.num_channels,
out_channels=args.num_channels, kernel_size=3,
stride=1)
self.conv4 = nn.Conv2d(in_channels=args.num_channels,
out_channels=args.num_channels, kernel_size=3,
stride=1)
self.bn1 = nn.BatchNorm2d(num_features=args.num_channels)
self.bn2 = nn.BatchNorm2d(num_features=args.num_channels)
self.bn3 = nn.BatchNorm2d(num_features=args.num_channels)
self.bn4 = nn.BatchNorm2d(num_features=args.num_channels)
self.fc1 = nn.Linear(in_features=args.num_channels * (self.board_x - 4) * (self.board_y - 4),
out_features=1024)
self.fc_bn1 = nn.BatchNorm1d(num_features=1024)
self.fc2 = nn.Linear(in_features=1024, out_features=512)
self.fc_bn2 = nn.BatchNorm1d(num_features=512)
self.fc3 = nn.Linear(in_features=512, out_features=self.action_size)
self.fc4 = nn.Linear(in_features=512, out_features=1)
def forward(self, s):
"""
Args:
s: np.ndarray
Array of size (batch_size x board_x x board_y)
Returns:
prob, v: tuple of torch.Tensor
Probability distribution over actions at the current state and the value
of the current state.
"""
s = s.view(-1, 1, self.board_x, self.board_y) # batch_size x 1 x board_x x board_y
s = F.relu(self.bn1(self.conv1(s))) # batch_size x num_channels x board_x x board_y
s = F.relu(self.bn2(self.conv2(s))) # batch_size x num_channels x board_x x board_y
s = F.relu(self.bn3(self.conv3(s))) # batch_size x num_channels x (board_x-2) x (board_y-2)
s = F.relu(self.bn4(self.conv4(s))) # batch_size x num_channels x (board_x-4) x (board_y-4)
s = s.view(-1, self.args.num_channels * (self.board_x - 4) * (self.board_y - 4))
s = F.dropout(F.relu(self.fc_bn1(self.fc1(s))), p=self.args.dropout, training=self.training) # batch_size x 1024
s = F.dropout(F.relu(self.fc_bn2(self.fc2(s))), p=self.args.dropout, training=self.training) # batch_size x 512
pi = self.fc3(s) # batch_size x action_size
v = self.fc4(s) # batch_size x 1
#################################################
## TODO for students: Compute the outputs of OthelloNNet in this order
# 1. Log softmax of linear layer 3
# 2. tanh of linear layer 4
# Fill out function and remove
raise NotImplementedError("Calculate the probability distribution and the value")
#################################################
# Returns probability distribution over actions at the current state and the value of the current state.
return ..., ...# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_OtheloNN_Excercise")セクション2.3: 価値ネットワークの定義
次に、上で作成したネットワークの訓練を実装する必要があります。価値関数を近似するように訓練したいので、実際の例(上記のエキスパートデータ)を使って訓練します。標準的な初期化、訓練、予測、損失関数を指定する必要があります。
コーディング演習 2.3: ValueNetwork を実装する
class ValueNetwork(NeuralNet):
def __init__(self, game):
"""
Args:
game: OthelloGame
Instance of the OthelloGame class above
"""
self.nnet = OthelloNNet(game, args)
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.nnet.to(args.device)
def train(self, games):
"""
Args:
games: list
List of examples with each example is of form (board, pi, v)
"""
optimizer = optim.Adam(self.nnet.parameters())
for examples in games:
for epoch in range(args.epochs):
print('EPOCH ::: ' + str(epoch + 1))
self.nnet.train()
v_losses = [] # To store the losses per epoch
batch_count = int(len(examples) / args.batch_size) # len(examples)=200, batch-size=64, batch_count=3
t = tqdm(range(batch_count), desc='Training Value Network')
for _ in t:
sample_ids = np.random.randint(len(examples), size=args.batch_size) # Read the ground truth information from MCTS simulation using the loaded examples
boards, pis, vs = list(zip(*[examples[i] for i in sample_ids])) # Length of boards, pis, vis = 64
boards = torch.FloatTensor(np.array(boards).astype(np.float64))
target_vs = torch.FloatTensor(np.array(vs).astype(np.float64))
# Predict
# To run on GPU if available
boards, target_vs = boards.contiguous().to(args.device), target_vs.contiguous().to(args.device)
#################################################
## TODO for students:
# 1. Compute the value predicted by OthelloNNet()
# 2. First implement the loss_v() function below and then use it to update the value loss. ##
# Fill out function and remove
raise NotImplementedError("Compute the output")
#################################################
# Compute output
_, out_v = ...
l_v = ... # Total loss
# Record loss
v_losses.append(l_v.item())
t.set_postfix(Loss_v=l_v.item())
# Compute gradient and do SGD step
optimizer.zero_grad()
l_v.backward()
optimizer.step()
def predict(self, board):
"""
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
Returns:
v: OthelloNet instance
Data of the OthelloNet class instance above;
"""
# Timing
start = time.time()
# Preparing input
board = torch.FloatTensor(board.astype(np.float64))
board = board.contiguous().to(args.device)
board = board.view(1, self.board_x, self.board_y)
self.nnet.eval()
with torch.no_grad():
_, v = self.nnet(board)
return v.data.cpu().numpy()[0]
def loss_v(self, targets, outputs):
"""
Calculates mean squared error
Args:
targets: np.ndarray
Ground Truth variables corresponding to input
outputs: np.ndarray
Predictions of Network
Returns:
MSE loss averaged across the whole dataset
"""
#################################################
## TODO for students: Please compute Mean squared error and return as output. ##
# Fill out function and remove
raise NotImplementedError("Calculate the loss")
#################################################
# Mean squared error (MSE)
return ...
def save_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
save_model_checkpoint(folder, filename, self.nnet)
def load_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
load_model_checkpoint(folder, filename, self.nnet, args.device)# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_the_Value_Network_Excercise")セクション2.4: 価値ネットワークの訓練とMSE損失の進行観察
重要: 次のセルは、rl_for_games リポジトリの事前学習済みモデルにアクセスできない場合に価値ネットワークを訓練します。
完了まで時間がかかるため、後述の rl_for_games リポジトリにある完全に訓練済みの価値ネットワークを使用することを推奨します。
if not os.listdir('nma_rl_games/alpha-zero/pretrained_models/models/'):
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.train(loaded_games)セクション2.5: 訓練済み価値ネットワークを使ってゲームをプレイする
価値ネットワークの準備と訓練が完了したので、これを使ってゲームをプレイしテストしましょう。
# @title Video 3: Play games using a value function
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'tvmzVHPBKKs'), ('Bilibili', 'BV1u54y1J7E6')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Play_games_using_a_value_function_Video")コーディング演習 2.5: 価値ベースのプレイヤーを実装する
演習:
- ランダムに有効な手をサンプリングし、価値関数でランク付けする
- 最も良い手を選択してプレイする
ランダムプレイヤーに勝つことを示す
ヒント: プレイヤーによって価値の符号を変える必要があるかもしれません。
まず新しいゲームを初期化し、事前学習済みの価値ネットワークを読み込みます。
model_save_name = 'ValueNetwork.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.load_checkpoint(folder=path, filename=model_save_name)次に、価値関数を使って次に取るべき最善の行動を決定するプレイヤーを作成します。
価値ネットワークを使って最善の手を選ぶには、全ての可能な手の期待値(予測価値)を計算し、次の状態の価値が最も高いものを選択します。
class ValueBasedPlayer():
def __init__(self, game, vnet):
"""
Args:
game: OthelloGame instance
Instance of the OthelloGame class above;
vnet: Value Network instance
Instance of the Value Network class above;
Returns: Nothing
"""
self.game = game
self.vnet = vnet
def play(self, board):
"""
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
Returns:
candidates: List
Collection of tuples describing action and values of future predicted
states
"""
valids = self.game.getValidMoves(board, 1)
candidates = []
max_num_actions = 4
va = np.where(valids)[0]
va_list = va.tolist()
random.shuffle(va_list)
#################################################
## TODO for students:
# 1. Use getNextState() to obtain the next board state,
# 2. Predict the value of the next state using the value network
# 3. Add the value and action as a tuple to the candidate list, after
# reversing the sign of the value.
# Note: In zero-sum games, the players alternate turns, and the value
# function is trained from the perspective of one player (either black or
# white). To estimate the value for the other player, we need to negate the
# output of the value function.
# For example, if the value function trained for the perspective of white
# suggests a high likelihood (0.75) of winning from the current state, it
# implies that black is very unlikely (-0.75) to win from the same state. ##
# Fill out function and remove
raise NotImplementedError("Implement the value-based player")
#################################################
for a in va_list:
# Return next board state using getNextState() function
nextBoard, _ = ...
# Predict the value of next state using value network
value = ...
# Add the value and the action as a tuple to the candidate lists, note that you might need to change the sign of the value based on the player
candidates += ...
if len(candidates) == max_num_actions:
break
# Sort by the values
candidates.sort()
# Return action associated with highest value
return candidates[0][1]
# Playing games between a value-based player and a random player
set_seed(seed=SEED)
num_games = 20
player1 = ValueBasedPlayer(game, vnet).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
## Uncomment the code below to check your code!
## Compute win rate for the value-based player (player 1)
# result = arena.playGames(num_games, verbose=False)
# print(f"\nNumber of games won by player1 = {result[0]}, "
# f"Number of games won by player2 = {result[1]} out of {num_games} games")
# win_rate_player1 = result[0]/num_games
# print(f"\nWin rate for player1 over 20 games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 15, プレイヤー2の勝利数 = 5 (20ゲーム中)
20ゲームにおけるプレイヤー1の勝率: 75.0%
# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_the_Value_based_player_Excercise")セクション3: エキスパートのゲームデータから方策ネットワークを学習する
所要時間の目安: 約35分
目標: 教師あり学習/行動模倣学習によって方策ネットワークを訓練する。
演習:
- エキスパートデータセットの次の手を予測するネットワークを、次の行動の対数尤度を最大化することで訓練する。
- 方策ネットワークを使ってゲームをプレイする。
ネットワークアーキテクチャの復習
# @title Video 4: Train a policy network
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'vj9gKNJ19D8'), ('Bilibili', 'BV1tg411M7Rg')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Train_a_policy_network_Video")セクション 3.1: ポリシーネットワークの定義
セクション2では、単純に次のステップの予測値が最も高い動きを選びました。ここでは異なるアプローチを取ります。現在の状態を入力として、すべての可能な離散的行動に対する分布としてポリシー関数を直接出力するネットワークを訓練します。学習は専門家の動きに基づくため、これを行動模倣(ビヘイビアクローニング)と呼びます。
価値関数学習に使ったのと全く同じネットワークを使用しますが、今回は専門家プレイヤーのすべての動きに対して明示的にネットワークを訓練します。
コーディング演習 3.1: PolicyNetwork の実装
目的関数の計算には、ターゲット の負の対数尤度をクロスエントロピー関数を用いて計算します:
注意: OthelloNet はすでに3番目の線形層の出力に対して対数ソフトマックスを返すことを覚えておいてください...
class PolicyNetwork(NeuralNet):
def __init__(self, game):
"""
Args:
game: OthelloGame
Instance of the OthelloGame class
"""
self.nnet = OthelloNNet(game, args)
self.board_x, self.board_y = game.getBoardSize()
self.action_size = game.getActionSize()
self.nnet.to(args.device)
def train(self, games):
"""
Args:
games: list
List of examples where each example is of form (board, pi, v)
"""
optimizer = optim.Adam(self.nnet.parameters())
for examples in games:
for epoch in range(args.epochs):
print('EPOCH ::: ' + str(epoch + 1))
self.nnet.train()
pi_losses = []
batch_count = int(len(examples) / args.batch_size)
t = tqdm(range(batch_count), desc='Training Policy Network')
for _ in t:
sample_ids = np.random.randint(len(examples), size=args.batch_size)
boards, pis, _ = list(zip(*[examples[i] for i in sample_ids]))
boards = torch.FloatTensor(np.array(boards).astype(np.float64))
target_pis = torch.FloatTensor(np.array(pis))
# Predict
boards, target_pis = boards.contiguous().to(args.device), target_pis.contiguous().to(args.device)
#################################################
## TODO for students:
# 1. Compute the policy (pi) predicted by OthelloNNet() ##
# 2. Implement the loss_pi() function below and then use it to update the policy loss. ##
# Fill out function and remove
raise NotImplementedError("Compute the output")
#################################################
# Compute output
out_pi, _ = ...
l_pi = ...
# Record loss
pi_losses.append(l_pi.item())
t.set_postfix(Loss_pi=l_pi.item())
# Compute gradient and do SGD step
optimizer.zero_grad()
l_pi.backward()
optimizer.step()
def predict(self, board):
"""
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
Returns:
Data from the OthelloNet instance
"""
# Timing
start = time.time()
# Preparing input
board = torch.FloatTensor(board.astype(np.float64))
board = board.contiguous().to(args.device)
board = board.view(1, self.board_x, self.board_y)
self.nnet.eval()
with torch.no_grad():
pi,_ = self.nnet(board)
return torch.exp(pi).data.cpu().numpy()[0]
def loss_pi(self, targets, outputs):
"""
Calculates Negative Log Likelihood(NLL) of Targets
Args:
targets: np.ndarray
Ground Truth variables corresponding to input
outputs: np.ndarray
Predictions of Network
Returns:
Negative Log Likelihood calculated as: When training a model, we aspire to
find the minima of a loss function given a set of parameters (in a neural
network, these are the weights and biases).
Sum the loss function to all the correct classes. So, whenever the network
assigns high confidence at the correct class, the NLL is low, but when the
network assigns low confidence at the correct class, the NLL is high.
"""
#################################################
## TODO for students: Return the negative log likelihood of targets.
# For more information, here is a reference that connects the expression to
# the neg-log-prob: https://gombru.github.io/2018/05/23/cross_entropy_loss/ ##
# Fill out function and remove
raise NotImplementedError("Compute the loss")
#################################################
return ...
def save_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
save_model_checkpoint(folder, filename, self.nnet)
def load_checkpoint(self, folder='checkpoint', filename='checkpoint.pth.tar'):
load_model_checkpoint(folder, filename, self.nnet, args.device)# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_the_Policy_Network_Exercise")セクション 3.2: ポリシーネットワークの訓練
重要: 次のセルは、rl_for_games リポジトリの事前学習済みモデルにアクセスできない場合のみ訓練を行います。
完了まで時間がかかるため、後述の rl_for_games リポジトリにある完全に訓練済みのポリシーネットワークを使用することを推奨します。
if not os.listdir('nma_rl_games/alpha-zero/pretrained_models/models/'):
set_seed(seed=SEED)
game = OthelloGame(6)
pnet = PolicyNetwork(game)
pnet.train(loaded_games)セクション 3.3: 訓練済みポリシーネットワークを使ってゲームをプレイする
# @title Video 6: Play games using a policy network
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'yHtVqT2Nstk'), ('Bilibili', 'BV1DU4y1n7gD')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)注意: 動画内のソフトマックス関数では、 がソフトマックスの温度パラメータで、 はソフトマックス変換前のネットワーク出力です。
# @title Submit your feedback
content_review(f"{feedback_prefix}_Play_games_using_a_Policy_Network_Video")コーディング演習 3.3: PolicyBasedPlayer の実装
演習:
- ポリシーネットワークを使って次の動きの確率を出す。
- ネットワークが最大確率を与えた動きを取るプレイヤーを作る。
- ネットワークの出力する確率分布に従って動きをサンプリングするプレイヤーと比較する。
まずゲームを初期化し、事前学習済みのポリシーネットワークを読み込みます。
model_save_name = 'PolicyNetwork.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
set_seed(seed=SEED)
game = OthelloGame(6)
pnet = PolicyNetwork(game)
pnet.load_checkpoint(folder=path, filename=model_save_name)次に、ポリシーネットワークを使って有効な盤面位置すべてに対する行動確率を出し、ポリシーベースのプレイヤーを作成します。
次の行動の選択方法は少なくとも2通りあります:
- サンプリングベースのプレイヤー: 行動確率分布からサンプリングします。確率が高い行動ほどランダムに選ばれる頻度が高くなります。
- グリーディプレイヤー: 常に最も高い行動確率の行動を選びます。
class PolicyBasedPlayer():
def __init__(self, game, pnet, greedy=True):
"""
Args:
game: OthelloGame instance
Instance of the OthelloGame class above;
pnet: Policy Network instance
Instance of the Policy Network class above
greedy: Boolean
If true, implement greedy approach
Else, implement random sample policy based player
"""
self.game = game
self.pnet = pnet
self.greedy = greedy
def play(self, board):
"""
Args:
board: np.ndarray
Board of size n x n [6x6 in this case]
Returns:
a: np.ndarray
If greedy, implement greedy policy player
Else, implement random sample policy based player
"""
valids = self.game.getValidMoves(board, 1)
#################################################
## TODO for students:
# 1. Compute the action probabilities using policy network pnet()
# 2. Mask invalid moves (set their action probability to 0) using valids
# variable and the action probabilites computed above.
# 3. Compute the sum over the probabilities of the valid actions and store
# them in sum_vap. ##
# Fill out function and remove
raise NotImplementedError("Define the play")
#################################################
action_probs = ...
vap = ... # Masking invalid moves
sum_vap = ...
if sum_vap > 0:
vap /= sum_vap # Renormalize
else:
# If all valid moves were masked we make all valid moves equally probable
print("All valid moves were masked, doing a workaround.")
vap = vap + valids
vap /= np.sum(vap)
if self.greedy:
# Greedy policy player
a = np.where(vap == np.max(vap))[0][0]
else:
# Sample-based policy player
a = np.random.choice(self.game.getActionSize(), p=vap)
return a
# Playing games
set_seed(seed=SEED)
num_games = 20
player1 = PolicyBasedPlayer(game, pnet, greedy=True).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
## Uncomment below to test!
# result = arena.playGames(num_games, verbose=False)
# print(f"\nNumber of games won by player1 = {result[0]}, "
# f"Number of games won by player2 = {result[1]} out of {num_games} games")
# win_rate_player1 = result[0] / num_games
# print(f"\nWin rate for greedy policy player 1 (vs random player 2) over {num_games} games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 16、プレイヤー2の勝利数 = 4(全20ゲーム中)
グリーディポリシープレイヤー1(対ランダムプレイヤー2)の20ゲームにおける勝率: 80.0%
# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_the_Policy_Based_Player_Exercise")セクション 4: プレイヤーの比較
所要時間の目安: 約5分
次に、異なるプレイヤー同士の対戦結果を比較します。すなわち、ランダムプレイヤー、価値ベースプレイヤー、ポリシーベースプレイヤー(グリーディまたはサンプリングベース)を比較します。下記に明示的に示していない比較も自由に試してみてください。
サンプリングベースのポリシーベースプレイヤーとランダムプレイヤーの比較
ゲーム数が少ない(計算時間の都合で20ゲームのみ)ため、結果にランダム性が含まれます。実行時に期待通りの結果が得られないこともあります。プレイヤーの強さをより正確に測るには、より多くのゲームを実行してください。
set_seed(seed=SEED)
num_games = 20
game = OthelloGame(6)
player1 = PolicyBasedPlayer(game, pnet, greedy=False).play
player2 = RandomPlayer(game).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
result = arena.playGames(num_games, verbose=False)
print(f"\nNumber of games won by player1 = {result[0]}, "
f"Number of games won by player2 = {result[1]} out of {num_games} games")
win_rate_player1 = result[0]/num_games
print(f"\nWin rate for sample-based policy based player 1 (vs random player 2) over {num_games} games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 12、プレイヤー2の勝利数 = 8(全20ゲーム中)
サンプリングベースのポリシーベースプレイヤー1(対ランダムプレイヤー2)の20ゲームにおける勝率: 60.0%
グリーディポリシーベースプレイヤーと価値ベースプレイヤーの比較
# @markdown Load in trained value network
model_save_name = 'ValueNetwork.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.load_checkpoint(folder=path, filename=model_save_name)
# Alternatively, if the downloading of trained model didn't work (will train the model)
if not os.listdir('nma_rl_games/alpha-zero/pretrained_models/models/'):
path = "nma_rl_games/alpha-zero/pretrained_models/data/"
loaded_games = loadTrainExamples(folder=path, filename='checkpoint_1.pth.tar')
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.train(loaded_games)set_seed(seed=SEED)
num_games = 20
game = OthelloGame(6)
player1 = PolicyBasedPlayer(game, pnet).play
player2 = ValueBasedPlayer(game, vnet).play
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
result = arena.playGames(num_games, verbose=False)
print(f"\nNumber of games won by player1 = {result[0]}, "
f"Number of games won by player2 = {result[1]} out of {num_games} games")
win_rate_player1 = result[0]/num_games
print(f"\nWin rate for greedy policy based player 1 (vs value based player) over {num_games} games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 7、プレイヤー2の勝利数 = 13(全20ゲーム中)
サンプリングベースのポリシーベースプレイヤー1(対ランダムプレイヤー2)の20ゲームにおける勝率: 35.0%
グリーディポリシーベースプレイヤーとサンプリングベースポリシープレイヤーの比較
set_seed(seed=SEED)
num_games = 20
game = OthelloGame(6)
player1 = PolicyBasedPlayer(game, pnet).play # greedy player
player2 = PolicyBasedPlayer(game, pnet, greedy=False).play # sample-based player
arena = Arena.Arena(player1, player2, game, display=OthelloGame.display)
result = arena.playGames(num_games, verbose=False)
print(f"\nNumber of games won by player1 = {result[0]}, "
f"Number of games won by player2 = {result[1]} out of {num_games} games")
win_rate_player1 = result[0]/num_games
print(f"\nWin rate for greedy policy player 1 (vs sample based policy player) over {num_games} games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 14、プレイヤー2の勝利数 = 6(全20ゲーム中)
グリーディポリシープレイヤー1(対サンプリングベースポリシープレイヤー)の20ゲームにおける勝率: 70.0%
グループで少し時間をとって、各プレイヤー(ランダムプレイヤー、価値ベースプレイヤー、グリーディポリシープレイヤー、サンプリングベースポリシープレイヤー)がどのように行動を選択しているかを振り返ってみましょう。
セクション 5: モンテカルロロールアウトを用いた計画
所要時間の目安: 約35分
目標: シミュレートされたロールアウトを使って未来を理解し、行動の価値を評価する基本的な考え方を学ぶ。
演習:
- ポリシーネットワークを用いたモンテカルロシミュレーションのループを構築する。
- シミュレートされたロールアウトを使って行動の価値のより良い推定を得る。
ネットワークアーキテクチャの復習
# @title Video 7: Play using Monte-Carlo rollouts
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'DtCWDIlSo18'), ('Bilibili', 'BV1MM4y1T77C')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Play_using_Monte_Carlo_Rollouts_Video")# @title Load in trained value and policy networks
model_save_name = 'ValueNetwork.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.load_checkpoint(folder=path, filename=model_save_name)
model_save_name = 'PolicyNetwork.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"
set_seed(seed=SEED)
game = OthelloGame(6)
pnet = PolicyNetwork(game)
pnet.load_checkpoint(folder=path, filename=model_save_name)
# Alternative if the downloading of trained model didn't work (will train the model)
if not os.listdir('nma_rl_games/alpha-zero/pretrained_models/models/'):
path = "nma_rl_games/alpha-zero/pretrained_models/data/"
loaded_games = loadTrainExamples(folder=path, filename='checkpoint_1.pth.tar')
set_seed(seed=SEED)
game = OthelloGame(6)
vnet = ValueNetwork(game)
vnet.train(loaded_games)
set_seed(seed=SEED)
game = OthelloGame(6)
pnet = PolicyNetwork(game)
pnet.train(loaded_games)セクション 5.1: モンテカルロプランナーの定義
復習すると、ここでのモンテカルロアルゴリズムの目的は、用いるポリシーに従った異なる計画の結果を評価すること、すなわち最終的にどのような将来の価値関数が得られるかを予測することです。したがって、ゲームのルールと特定の戦略に従って時間を進め、その反復の最後に価値関数の出力を返します。
コーディング演習 5.1: MonteCarlo プランナーの実装
ここではまずモンテカルロプランナーを設定します。
注意: 将来の異なる行動をシミュレート(計画)するため、実際に取られた盤面と区別したいです。したがって、モンテカルロシミュレーションの開始点として使う現在の(実際の)盤面は「正規化盤面(canonical board)」と呼んで混乱を避けます。
class MonteCarlo():
def __init__(self, game, nnet, args):
"""
Args:
game: OthelloGame instance
Instance of the OthelloGame class above;
nnet: OthelloNet instance
Instance of the OthelloNNet class above;
args: dictionary
Instantiates number of iterations and episodes, controls temperature threshold, queue length,
arena, checkpointing, and neural network parameters:
learning-rate: 0.001, dropout: 0.3, epochs: 10, batch_size: 64,
num_channels: 512
"""
self.game = game
self.nnet = nnet
self.args = args
self.Ps = {} # Stores initial policy (returned by neural net)
self.Es = {} # Stores game.getGameEnded ended for board s
def simulate(self, canonicalBoard):
"""
Simulate one Monte Carlo rollout
Args:
canonicalBoard: np.ndarray
Canonical Board of size n x n [6x6 in this case]
Returns:
temp_v:
Terminal State
"""
s = self.game.stringRepresentation(canonicalBoard)
init_start_state = s
temp_v = 0
isfirstAction = None
current_player = -1 # opponent's turn (the agent has already taken an action before the simulation)
self.Ps[s], _ = self.nnet.predict(canonicalBoard)
for i in range(self.args.maxDepth): # maxDepth
if s not in self.Es:
self.Es[s] = self.game.getGameEnded(canonicalBoard, 1)
if self.Es[s] != 0:
# Terminal state
temp_v = self.Es[s] * current_player
break
self.Ps[s], v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
self.Ps[s] = self.Ps[s] * valids # Masking invalid moves
sum_Ps_s = np.sum(self.Ps[s])
if sum_Ps_s > 0:
self.Ps[s] /= sum_Ps_s # Renormalize
else:
# If all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is
# insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay
# attention to your NNet and/or training process.
log.error("All valid moves were masked, doing a workaround.")
self.Ps[s] = self.Ps[s] + valids
self.Ps[s] /= np.sum(self.Ps[s])
##########################################################################
## TODO for students: Take a action according to the policy distribution.
# 1. Sample action according to the policy distribution.
# 2. Find the next state and the next player from the environment.
# 3. Get the canonical form of the next state.
# Fill out function and remove
raise NotImplementedError("Take the action, find the next state")
##########################################################################
# Choose action according to the policy distribution
a = ...
# Find the next state and the next player
next_s, next_player = self.game.getNextState(..., ..., ...)
canonicalBoard = self.game.getCanonicalForm(..., ...)
s = self.game.stringRepresentation(next_s)
current_player *= -1
# Initial policy
self.Ps[s], v = self.nnet.predict(canonicalBoard)
temp_v = v.item() * current_player
return temp_v# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_the_Monte_Carlo_Planner_Exercise")セクション 5.2: モンテカルロシミュレーションを使ってゲームをプレイする
目標: シンプルなモンテカルロ計画を使ってゲームをプレイする。
# @title Video 8: Play with planning
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'plmFzAy3H5s'), ('Bilibili', 'BV1Kg411M78Y')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Play_with_planning_Video")コーディング演習 5.2: モンテカルロシミュレーション
今からモンテカルロシミュレーションを実行します。現在の行動を取った場合の将来の結果を評価します。したがって、ポリシー(ランダム、価値ベース、ポリシーベース)に従って異なる将来の行動を選択し、その結果を評価します。潜在的な将来の結果をシミュレートし、その価値を計算して平均をとることで、現在の即時行動に対するポリシーの平均的な価値を把握します。この反復(ロールアウト)は以下の擬似コードで表せます:
for in to :
- 現在の状態 に対して特定のポリシー関数に従い、i番目にランク付けされた行動 を選択する。
- を適用した後の状態 から、深さ まで 回のモンテカルロロールアウトを実行する。
- 各ロールアウトの推定値の平均を計算し、 とする。
- のペアの配列を作成する。
行動を選択する際は、平均価値が最も高い行動、すなわち を選びます。ここでは 、、 を使用します。
演習:
- モンテカルロシミュレーションをエージェントに組み込む。
- そのプレイヤーをランダム、価値ベース、ポリシーベースのプレイヤーと対戦させる。
# Load MC model from the repository
mc_model_save_name = 'MC.pth.tar'
path = "nma_rl_games/alpha-zero/pretrained_models/models/"class MonteCarloBasedPlayer():
"""
Simulate Player based on Monte Carlo Algorithm
"""
def __init__(self, game, nnet, args):
"""
Args:
game: OthelloGame instance
Instance of the OthelloGame class above;
nnet: OthelloNet instance
Instance of the OthelloNNet class above;
args: dictionary
Instantiates number of iterations and episodes, controls temperature threshold, queue length,
arena, checkpointing, and neural network parameters:
learning-rate: 0.001, dropout: 0.3, epochs: 10, batch_size: 64,
num_channels: 512
"""
self.game = game
self.nnet = nnet
self.args = args
############################################################################
## TODO for students: Instantiate the Monte Carlo class.
# Fill out function and remove
raise NotImplementedError("Use Monte Carlo!")
############################################################################
self.mc = ...
self.K = self.args.mc_topk
def play(self, canonicalBoard):
"""
Args:
canonicalBoard: np.ndarray
Canonical Board of size n x n [6x6 in this case]
Returns:
best_action: tuple
(avg_value, action) i.e., Average value associated with corresponding
action, i.e., Action with the highest topK probability
"""
self.qsa = []
s = self.game.stringRepresentation(canonicalBoard)
Ps, v = self.nnet.predict(canonicalBoard)
valids = self.game.getValidMoves(canonicalBoard, 1)
Ps = Ps * valids # Masking invalid moves
sum_Ps_s = np.sum(Ps)
if sum_Ps_s > 0:
Ps /= sum_Ps_s # Renormalize
else:
# If all valid moves were masked make all valid moves equally probable
# NB! All valid moves may be masked if either your NNet architecture is insufficient or you've get overfitting or something else.
# If you have got dozens or hundreds of these messages you should pay attention to your NNet and/or training process.
log = logging.getLogger(__name__)
log.error("All valid moves were masked, doing a workaround.")
Ps = Ps + valids
Ps /= np.sum(Ps)
num_valid_actions = np.shape(np.nonzero(Ps))[1]
if num_valid_actions < self.K:
top_k_actions = np.argpartition(Ps,-num_valid_actions)[-num_valid_actions:]
else:
top_k_actions = np.argpartition(Ps,-self.K)[-self.K:] # To get actions that belongs to top k prob
############################################################################
## TODO for students:
# 1. For each action in the top-k actions
# 2. Get the next state using getNextState() function.
# You can find the implementation of this function in Tutorial 1 in
# `OthelloGame()` class.
# 3. Get the canonical form of the getNextState().
# Fill out function and remove
raise NotImplementedError("Loop for the top actions")
############################################################################
for action in ...:
next_s, next_player = self.game.getNextState(..., ..., ...)
next_s = self.game.getCanonicalForm(..., ...)
values = []
# Do some rollouts
for rollout in range(self.args.numMCsims):
value = self.mc.simulate(next_s)
values.append(value)
# Average out values
avg_value = np.mean(values)
self.qsa.append((avg_value, action))
self.qsa.sort(key=lambda a: a[0])
self.qsa.reverse()
best_action = self.qsa[0][1]
return best_action
def getActionProb(self, canonicalBoard, temp=1):
"""
Get probabilities associated with each action
Args:
canonicalBoard: np.ndarray
Canonical Board of size n x n [6x6 in this case]
temp: Integer
Signifies if game is in terminal state
Returns:
action_probs: List
Probability associated with corresponding action
"""
if self.game.getGameEnded(canonicalBoard, 1) != 0:
return np.zeros((self.game.getActionSize()))
else:
action_probs = np.zeros((self.game.getActionSize()))
best_action = self.play(canonicalBoard)
action_probs[best_action] = 1
return action_probs
set_seed(seed=SEED)
game = OthelloGame(6)
# Run the resulting player versus the random player
rp = RandomPlayer(game).play
num_games = 20 # Feel free to change this number
n1 = NNet(game) # nNet players
n1.load_checkpoint(folder=path, filename=mc_model_save_name)
args1 = dotdict({'numMCsims': 10, 'maxRollouts':5, 'maxDepth':5, 'mc_topk': 3})
## Uncomment below to check Monte Carlo agent!
# print('\n******MC player versus random player******')
# mc1 = MonteCarloBasedPlayer(game, n1, args1)
# n1p = lambda x: np.argmax(mc1.getActionProb(x))
# arena = Arena.Arena(n1p, rp, game, display=OthelloGame.display)
# MC_result = arena.playGames(num_games, verbose=False)
# print(f"\nNumber of games won by player1 = {MC_result[0]}, "
# f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
# win_rate_player1 = MC_result[0]/num_games
# print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 19、プレイヤー2の勝利数 = 1(全20ゲーム中)
プレイヤー1の20ゲームにおける勝率: 95.0%
# @title Submit your feedback
content_review(f"{feedback_prefix}_Monte_Carlo_simulations_Exercise")モンテカルロプレイヤー vs 価値ベースプレイヤー
print('\n******MC player versus value-based player******')
set_seed(seed=SEED)
vp = ValueBasedPlayer(game, vnet).play # Value-based player
arena = Arena.Arena(n1p, vp, game, display=OthelloGame.display)
MC_result = arena.playGames(num_games, verbose=False)
print(f"\nNumber of games won by player1 = {MC_result[0]}, "
f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
win_rate_player1 = MC_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 17、プレイヤー2の勝利数 = 3(全20ゲーム中)
プレイヤー1の20ゲームにおける勝率: 85.0%
モンテカルロプレイヤー vs ポリシーベースプレイヤー
print('\n******MC player versus policy-based player******')
set_seed(seed=SEED)
pp = PolicyBasedPlayer(game, pnet).play # Policy player
arena = Arena.Arena(n1p, pp, game, display=OthelloGame.display)
MC_result = arena.playGames(num_games, verbose=False)
print(f"\nNumber of games won by player1 = {MC_result[0]}, "
f"number of games won by player2 = {MC_result[1]}, out of {num_games} games")
win_rate_player1 = MC_result[0]/num_games
print(f"\nWin rate for player1 over {num_games} games: {round(win_rate_player1*100, 1)}%")プレイヤー1の勝利数 = 18、プレイヤー2の勝利数 = 2(全20ゲーム中)
プレイヤー1の20ゲームにおける勝率: 90.0%
セクション 6: 倫理的側面
所要時間の目安: 約5分
# @title Video 9: Unbeatable opponents
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'q7181lvoNpM'), ('Bilibili', 'BV19M4y1K75Z')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Unbeatable_opponents_Video")まとめ
このチュートリアルで学んだこと:
- オセロゲームの概要、ゲームループの実装方法、ランダムプレイヤーの作成方法
- 価値ベースプレイヤーの作成とランダムプレイヤーとの比較
- ポリシーベースプレイヤーの作成とランダムおよび価値ベースプレイヤーとの比較
- モンテカルロプランナーを用いたプレイヤーの作成とランダム、価値ベース、ポリシーベースプレイヤーとの比較
# @title Video 19: Outro
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'uQ26iIUzmtw'), ('Bilibili', 'BV1w64y167qd')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Outro_Video")