![]()

チュートリアル 2: 行動を学ぶ:マルチアームドバンディット
第3週、第4日目:強化学習
Neuromatch Academyによる
コンテンツ作成者: Marcelo G Mattar, Eric DeWitt, Matt Krause, Matthew Sargent, Anoop Kulkarni, Sowmya Parthiban, Feryal Behbahani, Jane Wang
コンテンツレビュアー: Ella Batty, Byron Galbraith, Michael Waskom, Ezekiel Williams, Mehul Rastogi, Lily Cheng, Roberto Guidotti, Arush Tagade, Kelson Shilling-Scrivo
制作編集者: Gagana B, Spiros Chavlis
チュートリアルの目的
チュートリアルの推定所要時間:45分
このチュートリアルでは、最も単純なタイプの行動エージェントをモデル化します。行動エージェントは受け取る報酬に影響を与えることができるため、最も多くの報酬をもたらす行動を特定する方法を学ばなければなりません。『バンディット』を使って、強化学習におけるポリシーと学習アルゴリズムの基本的な相互作用を理解します。
- ポリシーにおける探索と活用の基本的なトレードオフを理解します。
- 学習率が探索とどのように相互作用して最適な行動を見つけるかを理解します。
# @title Tutorial slides
# @markdown These are the slides for all videos in this tutorial.
from IPython.display import IFrame
link_id = "2jzdu"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)セットアップ
# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W3D4_T2"# Imports
import numpy as np
import matplotlib.pyplot as plt# @title Figure Settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
import ipywidgets as widgets # interactive display
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")# @title Plotting Functions
np.set_printoptions(precision=3)
def plot_choices(q, epsilon, choice_fn, n_steps=1000, rng_seed=1):
np.random.seed(rng_seed)
counts = np.zeros_like(q)
for t in range(n_steps):
action = choice_fn(q, epsilon)
counts[action] += 1
fig, ax = plt.subplots()
ax.bar(range(len(q)), counts/n_steps)
ax.set(ylabel='% chosen', xlabel='action', ylim=(0,1), xticks=range(len(q)))
plt.show()
def plot_multi_armed_bandit_results(results):
fig, (ax1, ax2, ax3) = plt.subplots(ncols=3, figsize=(15, 5))
ax1.plot(results['rewards'])
ax1.set(title=f"Total Reward: {np.sum(results['rewards']):.2f}",
xlabel='step', ylabel='reward')
ax2.plot(results['qs'])
ax2.set(xlabel='step', ylabel='value')
ax2.legend(range(len(results['mu'])))
ax3.plot(results['mu'], label='latent')
ax3.plot(results['qs'][-1], label='learned')
ax3.set(xlabel='action', ylabel='value')
ax3.legend()
plt.show()
def plot_parameter_performance(labels, fixed, trial_rewards, trial_optimal):
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(16, 6))
ax1.plot(np.mean(trial_rewards, axis=1).T)
ax1.set(title=f'Average Reward ({fixed})', xlabel='step', ylabel='reward')
ax1.legend(labels)
ax2.plot(np.mean(trial_optimal, axis=1).T)
ax2.set(title=f'Performance ({fixed})', xlabel='step', ylabel='% optimal')
ax2.legend(labels)
plt.show()セクション 1: マルチアームドバンディット
# @title Video 1: Multi-Armed Bandits
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'kdiXr1zsfo0'), ('Bilibili', 'BV1M54y1B7S3')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_MultiArmed_Bandits_Video")以下の学習問題を考えます。あなたは繰り返し 個の異なる選択肢、つまり行動の中から選択を迫られます。各選択の後に、数値として表される報酬信号を受け取ります。数値が大きいほど良い報酬です。あなたの目的は、例えば1000回の行動選択や時間ステップにわたって、期待される総報酬を最大化することです。
これは k-armed bandit 問題の元々の形です。この名前はスロットマシンの俗称「one-armed bandit(一つ腕の強盗)」に由来します。これはレバーが一つだけで、時間が経つにつれて支払うよりも多くのお金を取るように仕組まれていることが多いからです。multi-armed bandit の拡張は、例えば複数のスロットマシンがあり、一度に一台だけ遊べると想像することです。どのマシンを遊ぶべきか、すなわちどのアームを引くべきか、どの行動を取るべきかを決めて、総払い戻しを最大化します。
報酬の決定方法にはさまざまな複雑さや仮定がありますが、ここでは各行動が平均不明で分散が1の異なるガウス分布から報酬を得るという単純なシナリオを考えます。各行動は異なる平均報酬に対応しているため、エージェントの目標は平均が最も高い行動を見つけることです。しかし報酬はノイズを含む(対応するガウス分布は分散1)ため、単一の観測報酬から平均を特定することはできません。
この問題設定は環境と呼ばれます。これを最適化問題として、報酬を入力に取り行動を返すエージェント、つまりアルゴリズムで解きます。
セクション 2: 行動の選択
チュートリアル開始からここまでの推定所要時間: 10分
エージェントが最初にできるようにしなければならないことは、どのアームを引くかを選ぶことです。期待値に基づいて行動を選択する戦略は方策(しばしば と表されます)と呼ばれます。ランダムな方策、つまり毎回ランダムにアームを選ぶという方法もありますが、これは報酬を最適化できるとは考えにくいです。私たちは意図的な選択をしたいので、そのためにはアームの報酬の可能性に関する信念を表現する方法が必要です。これを行動価値関数で表します。
ここで、時刻 に行動 を取ったときの価値 は、その時に行動 を取った場合の報酬 の期待値に等しいです。実際には、これは各行動の価値が配列の異なる要素として表されることが多いです。
さて、各行動が返すべき価値に関する信念を表現する方法ができたので、方策を考えてみましょう。
明らかな選択肢は、期待値が最も高い行動を取ることです。これは貪欲方策と呼ばれます。
ここで、選択する行動は現在の価値関数を最大化するものです。
ここまでは順調ですが、そんなに簡単なはずはありません。実際、貪欲方策には致命的な欠点があります。それは局所最大値に簡単に陥ってしまうことです。ある選択肢が他よりも良い場合、それ以外の選択肢を探索しようとしません。これが効果的な方策を考える上での根本的な課題につながります。
搾取-探索ジレンマ
もし新しいことに一切挑戦せず、常に安全な選択肢に固執してしまうと、何を見逃しているのか分かりません。時にはほとんど何も見逃しておらず、好みの選択肢に固執しなかったことを後悔することもありますが、他の時には思っていたよりずっと良い新しい何かに偶然出会うこともあります。
これが搾取-探索ジレンマです:今の最善の選択を取るべきか、それともより良いものを見つけることを期待して不確かな選択肢をリスクを取って試すべきか。探索をやりすぎると、やめる時に最適でない報酬を得てしまう可能性があります。
局所的な最小値に陥るのを避けつつ報酬を最大化するために、効果的な方策はこれら二つの目的のバランスを取る方法が必要です。
貪欲方策の簡単な拡張として、いくつかのランダム性を加える方法があります。例えば、コイントスで表なら今の最善の選択を取り、裏ならランダムに選ぶという方法です。これを-貪欲方策と呼びます:
これは、に対して確率で貪欲な選択をし、それ以外はランダムに(貪欲な選択肢も含めて)行動を選ぶことを意味します。
比較的単純ながら、-貪欲方策は非常に効果的であり、そのため広く使われています。
コーディング演習 2: Epsilon-Greedy の実装
動画内では演習1として紹介されています
この演習では、価値関数と確率に基づいて、可能な行動の中からどの行動を取るかを決定する-貪欲アルゴリズムを実装します。は単純にランダムに行動を選ぶ確率です。
ヒント:ここでは np.random.random、np.random.choice、および np.argmax が役立つでしょう。
def epsilon_greedy(q, epsilon):
"""Epsilon-greedy policy: selects the maximum value action with probability
(1-epsilon) and selects randomly with epsilon probability.
Args:
q (ndarray): an array of action values
epsilon (float): probability of selecting an action randomly
Returns:
int: the chosen action
"""
#####################################################################
## TODO for students: implement the epsilon greedy decision algorithm
# Fill out function and remove
raise NotImplementedError("Student exercise: implement the epsilon greedy decision algorithm")
#####################################################################
# write a boolean expression that determines if we should take the best action
be_greedy = ...
if be_greedy:
# write an expression for selecting the best action from the action values
action = ...
else:
# write an expression for selecting a random action
action = ...
return action
# Set parameters
q = [-2, 5, 0, 1]
epsilon = 0.1
# Visualize
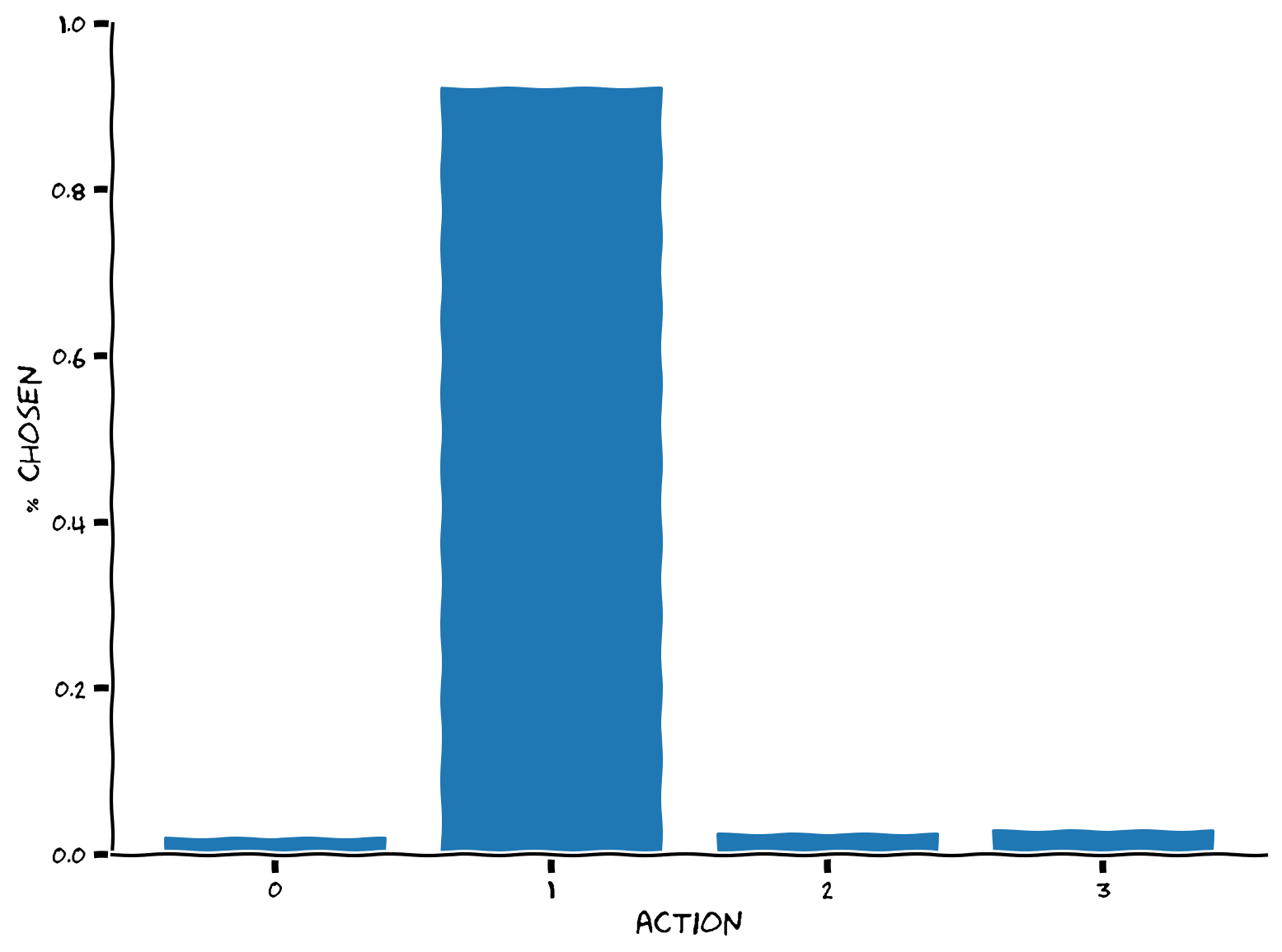
plot_choices(q, epsilon, epsilon_greedy)出力例:
# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_epsilon_greedy_Exercise")期待される結果は、最大の価値を持つ行動(行動1)が約(1-)、すなわちの場合は90%の確率で選択され、残りの10%は他の選択肢に均等に分配されるということです。以下のデモを使って、を変化させたときに選択される行動の分布がどう変わるかを試してみてください。
インタラクティブデモ 2: Epsilonの変更
Epsilonは搾取と探索のバランスを取るための唯一のパラメータです。価値のセットを用いて、下のウィジェットでを変化させると、最大値5(行動=1)とその他の選択肢の選択がどのように変わるかを確認できます。
の範囲の端(0と1)では、-貪欲方策は他の2つの方策を再現します。それらは何でしょうか?
# @markdown Make sure you execute this cell to enable the widget!
@widgets.interact(epsilon=widgets.FloatSlider(0.1, min=0.0, max=1.0,
description="ε"))
def explore_epilson_values(epsilon=0.1):
q = [-2, 5, 0, 1]
plot_choices(q, epsilon, epsilon_greedy, rng_seed=None)# @title Submit your feedback
content_review(f"{feedback_prefix}_Changing_epsilon_Interactive_Demo_and_Discussion")セクション3: 報酬から学ぶ
チュートリアル開始からここまでの推定所要時間: 25分
行動を決定するための方策ができたので、次は行動からどのように学習するかを考えましょう。
一つの方法は、これまでに得たすべての結果を記録し、それぞれの行動の平均を使うことです。もしエピソードが非常に長く続く可能性がある場合、これらすべての値を保持し、平均を何度も再計算する計算コストは理想的ではありません。代わりに、ストリーミング平均計算を使うことができます。これは次のようになります:
ここで、行動価値関数 はこれまでに見た報酬の平均、 は時刻 までに取った行動の回数、 は行動 を取った直後に得た報酬です。
これでも取った行動の回数を覚えておく必要があるので、もう少し一般化して、行動の合計を一般的なパラメータ (学習率と呼びます)に置き換えましょう。
コーディング演習3: 行動価値の更新
ビデオ内では演習2として言及されています
この演習では、上記の行動価値更新ルールを実装します。関数は、配列 q で表された行動価値関数、取った行動、受け取った報酬、学習率 alpha を引数に取り、選択した行動の更新された価値を返します。
def update_action_value(q, action, reward, alpha):
""" Compute the updated action value given the learning rate and observed
reward.
Args:
q (ndarray): an array of action values
action (int): the action taken
reward (float): the reward received for taking the action
alpha (float): the learning rate
Returns:
float: the updated value for the selected action
"""
#####################################################
## TODO for students: compute the action value update
# Fill out function and remove
raise NotImplementedError("Student exercise: compute the action value update")
#####################################################
# Write an expression for the updated action value
value = ...
return value
# Set parameters
q = [-2, 5, 0, 1]
action = 2
print(f"Original q({action}) value = {q[action]}")
# Update action
q[action] = update_action_value(q, 2, 10, 0.01)
print(f"Updated q({action}) value = {q[action]}")以下のように表示されるはずです
元の q(2) の値 = 0
更新後の q(2) の値 = 0.1
# @title Submit your feedback
content_review(f"{feedback_prefix}_Updating_Action_Values_Exercise")セクション4: マルチアームドバンディットの解決
チュートリアル開始からここまでの推定所要時間: 31分
方策と学習ルールの両方ができたので、これらを組み合わせて元のマルチアームドバンディット問題を解いてみましょう。報酬は平均不明で分散1のガウス分布から引かれ、腕の数は複数あるという設定で、目標は平均が最も高い腕を見つけることです。
まずは、以下の注釈付きコードを読みながら、この環境をどのようにシミュレートするか見てみましょう。
def multi_armed_bandit(n_arms, epsilon, alpha, n_steps):
""" A Gaussian multi-armed bandit using an epsilon-greedy policy. For each
action, rewards are randomly sampled from normal distribution, with a mean
associated with that arm and unit variance.
Args:
n_arms (int): number of arms or actions
epsilon (float): probability of selecting an action randomly
alpha (float): the learning rate
n_steps (int): number of steps to evaluate
Returns:
dict: a dictionary containing the action values, actions, and rewards from
the evaluation along with the true arm parameters mu and the optimality of
the chosen actions.
"""
# Gaussian bandit parameters
mu = np.random.normal(size=n_arms)
# Evaluation and reporting state
q = np.zeros(n_arms)
qs = np.zeros((n_steps, n_arms))
rewards = np.zeros(n_steps)
actions = np.zeros(n_steps)
optimal = np.zeros(n_steps)
# Run the bandit
for t in range(n_steps):
# Choose an action
action = epsilon_greedy(q, epsilon)
actions[t] = action
# Compute rewards for all actions
all_rewards = np.random.normal(mu)
# Observe the reward for the chosen action
reward = all_rewards[action]
rewards[t] = reward
# Was it the best possible choice?
optimal_action = np.argmax(all_rewards)
optimal[t] = action == optimal_action
# Update the action value
q[action] = update_action_value(q, action, reward, alpha)
qs[t] = q
results = {
'qs': qs,
'actions': actions,
'rewards': rewards,
'mu': mu,
'optimal': optimal
}
return resultsマルチアームドバンディットの手法を使って、イプシロン・グリーディ方策と学習ルールがタスク解決にどのように機能するか評価できます。まず環境の腕の数を10に設定し、エージェントのパラメータを 、 にします。エージェントの性能をよく把握するために、エピソードを1000ステップ実行します。
# @markdown Execute to see visualization
# set for reproducibility, comment out / change seed value for different results
np.random.seed(1)
n_arms = 10
epsilon = 0.1
alpha = 0.01
n_steps = 1000
results = multi_armed_bandit(n_arms, epsilon, alpha, n_steps)
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(16, 6))
ax1.plot(results['rewards'])
ax1.set(title=f'Observed Reward ($\epsilon$={epsilon}, $\\alpha$={alpha})',
xlabel='step', ylabel='reward')
ax2.plot(results['qs'])
ax2.set(title=f'Action Values ($\epsilon$={epsilon}, $\\alpha$={alpha})',
xlabel='step', ylabel='value')
ax2.legend(range(n_arms))
plt.show(fig)さて、報酬はかなりばらつきがありますが、エージェントは比較的早く最初の腕を好む行動として定着させたようです。腕の背後にあるガウス分布の真の平均をどれだけうまく推定できたか見てみましょう。
# @markdown Execute to see visualization
fig, ax = plt.subplots()
ax.plot(results['mu'], label='latent')
ax.plot(results['qs'][-1], label='learned')
ax.set(title=f'$\epsilon$={epsilon}, $\\alpha$={alpha}',
xlabel='action', ylabel='value')
ax.legend()
plt.show(fig)行動0の推定は非常に良好ですが、他の多くはあまり良くありません。実際、局所最大値の罠の影響が見て取れます。アルゴリズムのグリーディ部分が行動0に固執してしまい、これは実は行動6に次ぐ2番目に良い選択肢です。これらはガウス分布の平均なので、両者の分布がかなり重なっていることがわかります。したがって、行動6を探索しても、行動0の推定値より低いサンプルを引く可能性があります。
しかし、これはパラメータの一例に過ぎません。より良い組み合わせがあるかもしれません。
インタラクティブデモ4: イプシロンとアルファの変更
ビデオ内では演習3として言及されています
以下のウィジェットを使って、(搾取と探索のトレードオフ)、(学習率)、さらには行動数 を変化させることで、エージェントの挙動がどう変わるかを探ってみましょう。
# @markdown Make sure you execute this cell to enable the widget!
@widgets.interact_manual(k=widgets.IntSlider(10, min=2, max=15),
epsilon=widgets.FloatSlider(0.1, min=0.0, max=1.0,
description="ε"),
alpha=widgets.FloatLogSlider(0.01, min=-3, max=0,
description="α"))
def explore_bandit_parameters(k=10, epsilon=0.1, alpha=0.001):
results = multi_armed_bandit(k, epsilon, alpha, 1000)
plot_multi_armed_bandit_results(results)イプシロンとアルファの値を変えることでエージェントの挙動にどう影響するかは見えますが、どの組み合わせが最適かを知るには不十分です。報酬と方策の確率的性質のため、単一の試行では十分な情報が得られません。複数回の試行を行い、平均的な性能を比較しましょう。
まず、 の異なる値を固定の で試します。速度と精度のバランスを考え、200回の試行を行います。
# @markdown Execute this cell to see visualization
# set for reproducibility, comment out / change seed value for different results
np.random.seed(1)
epsilons = [0.0, 0.1, 0.2]
alpha = 0.1
n_trials = 200
trial_rewards = np.zeros((len(epsilons), n_trials, n_steps))
trial_optimal = np.zeros((len(epsilons), n_trials, n_steps))
for i, epsilon in enumerate(epsilons):
for n in range(n_trials):
results = multi_armed_bandit(n_arms, epsilon, alpha, n_steps)
trial_rewards[i, n] = results['rewards']
trial_optimal[i, n] = results['optimal']
labels = [f'$\epsilon$={e}' for e in epsilons]
fixed = f'$\\alpha$={alpha}'
plot_parameter_performance(labels, fixed, trial_rewards, trial_optimal)左のグラフは時間経過に伴う平均報酬を示しており、(グリーディ方策)は最初は良い結果を出しますが、 は長期的にわずかに良くなり、 は最も悪い結果となっています。右のグラフは最適行動(時刻 における最良の選択)が取られた割合を示し、ここでも が最初はやや遅いものの、長期的にはわずかに優位に立っています。
同様に学習率についても評価します。 を固定の で試します。
# @markdown Execute this cell to see visualization
# set for reproducibility, comment out / change seed value for different results
np.random.seed(1)
epsilon = 0.1
alphas = [0.01, 0.1, 1.0]
n_trials = 200
trial_rewards = np.zeros((len(epsilons), n_trials, n_steps))
trial_optimal = np.zeros((len(epsilons), n_trials, n_steps))
for i, alpha in enumerate(alphas):
for n in range(n_trials):
results = multi_armed_bandit(n_arms, epsilon, alpha, n_steps)
trial_rewards[i, n] = results['rewards']
trial_optimal[i, n] = results['optimal']
labels = [f'$\\alpha$={a}' for a in alphas]
fixed = f'$\epsilon$={epsilon}'
plot_parameter_performance(labels, fixed, trial_rewards, trial_optimal)ここでも効果的な学習率のバランスが見られます。 は良い値を素早く取り込むには弱すぎ、 は報酬のガウス性質のため値の分散が大きくなりすぎる可能性があります。
# @title Submit your feedback
content_review(f"{feedback_prefix}_Changing_Epsilon_and_Alpha_Interactive_Demo")まとめ
チュートリアルの推定所要時間: 45分
このチュートリアルでは、イプシロン・グリーディ決定アルゴリズムとマルチアームドバンディット問題を解くための学習ルールの両方を実装しました。行動選択における搾取と探索のバランスが最適解を見つける上で重要であることを学びました。また、適切な学習率の選択が、報酬から得られる情報をどれだけうまく一般化できるかを決定することも理解しました。