![]()

チュートリアル 3: カルマンフィルター
第3週、第3日目: 隠れた動力学
Neuromatch Academyによる
コンテンツ制作者: イツェル・オリボス・カスティーヨ、ザック・ピトコウ
制作編集: ガガナ B、スピロス・チャヴリス
参考文献:
- Roweis, Ghahramani (1998): 線形ガウスモデルの統一的レビュー
- Bishop (2006): パターン認識と機械学習
チュートリアルの目的
チュートリアルの推定所要時間: 1時間15分
これまでのチュートリアルでは、隠れマルコフモデル(HMM)を用いて、観測データ列から離散的な潜在状態を推定しました。本チュートリアルでは、カルマンフィルターというHMMの一種を用いて、連続的な潜在変数を推定する方法を学びます。
このチュートリアルで学ぶこと:
- 線形動的システムの復習
- 1次元カルマンフィルターの理解
- プロセスのパラメータを操作してカルマンフィルターの挙動を観察
- カルマンフィルターの基本的な性質について考察
この推定過程は、ミッションコントロールがアストロキャットの位置を特定・追跡しようとする様子を想像できます。また、脳が類似の隠れマルコフモデルを使って世界の物体を追跡したり、自身の行動の結果を推定したりしているとも考えられます。この技術は、脳活動をノイズの多い計測から推定し、理解や脳-機械インターフェースの構築に役立てることもできます。
# @title Tutorial slides
# @markdown These are the slides for all videos in this tutorial.
from IPython.display import IFrame
link_id = "r7q5u"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)セットアップ
# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W3D2_T3"# Imports
import pandas as pd
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import transforms
from collections import namedtuple
from scipy.stats import norm# @title Figure Settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
import ipywidgets as widgets # interactive display
from ipywidgets import interactive, interact, HBox, Layout,VBox
from IPython.display import HTML
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")# @title Plotting Functions
def visualize_Astrocat(s, T):
plt.plot(s, color='limegreen', lw=2)
plt.plot([T], [s[-1]], marker='o', markersize=8, color='limegreen')
plt.xlabel('Time t')
plt.ylabel('s(t)')
plt.show()
def plot_measurement(s, m, T):
plt.plot(s, color='limegreen', lw=2, label='true position')
plt.plot([T], [s[-1]], marker='o', markersize=8, color='limegreen')
plt.plot(m, '.', color='crimson', lw=2, label='measurement')
plt.xlabel('Time t')
plt.ylabel('s(t)')
plt.legend()
plt.show()
def plot_function(u=1,v=2,w=3,x=4,y=5,z=6):
time = np.arange(0, 1, 0.01)
df = pd.DataFrame({"y1":np.sin(time*u*2*np.pi),
"y2":np.sin(time*v*2*np.pi),
"y3":np.sin(time*w*2*np.pi),
"y4":np.sin(time*x*2*np.pi),
"y5":np.sin(time*y*2*np.pi),
"y6":np.sin(time*z*2*np.pi)})
df.plot()# @title Helper Functions
gaussian = namedtuple('Gaussian', ['mean', 'cov'])
def filter(D, process_noise, measurement_noise, posterior, m):
todays_prior = gaussian(D * posterior.mean, D**2 * posterior.cov + process_noise)
likelihood = gaussian(m, measurement_noise)
info_prior = 1/todays_prior.cov
info_likelihood = 1/likelihood.cov
info_posterior = info_prior + info_likelihood
prior_weight = info_prior / info_posterior
likelihood_weight = info_likelihood / info_posterior
posterior_mean = prior_weight * todays_prior.mean + likelihood_weight * likelihood.mean
posterior_cov = 1/info_posterior
todays_posterior = gaussian(posterior_mean, posterior_cov)
"""
prior = gaussian(belief.mean, belief.cov)
predicted_estimate = D * belief.mean
predicted_covariance = D**2 * belief.cov + process_noise
likelihood = gaussian(m, measurement_noise)
innovation_estimate = m - predicted_estimate
innovation_covariance = predicted_covariance + measurement_noise
K = predicted_covariance / innovation_covariance # Kalman gain, i.e. the weight given to the difference between the measurement and predicted measurement
updated_mean = predicted_estimate + K * innovation_estimate
updated_cov = (1 - K) * predicted_covariance
todays_posterior = gaussian(updated_mean, updated_cov)
"""
return todays_prior, likelihood, todays_posterior
def paintMyFilter(D, initial_guess, process_noise, measurement_noise, s, m, s_, cov_):
# Compare solution with filter function
filter_s_ = np.zeros(T) # estimate (posterior mean)
filter_cov_ = np.zeros(T) # uncertainty (posterior covariance)
posterior = initial_guess
filter_s_[0] = posterior.mean
filter_cov_[0] = posterior.cov
process_noise_std = np.sqrt(process_noise)
measurement_noise_std = np.sqrt(measurement_noise)
for i in range(1, T):
prior, likelihood, posterior = filter(D, process_noise, measurement_noise, posterior, m[i])
filter_s_[i] = posterior.mean
filter_cov_[i] = posterior.cov
smin = min(min(m),min(s-2*np.sqrt(cov_[-1])), min(s_-2*np.sqrt(cov_[-1])))
smax = max(max(m),max(s+2*np.sqrt(cov_[-1])), max(s_+2*np.sqrt(cov_[-1])))
pscale = 0.2 # scaling factor for displaying pdfs
fig = plt.figure(figsize=[15, 10])
ax = plt.subplot(2, 1, 1)
ax.set_xlabel('time')
ax.set_ylabel('state')
ax.set_xlim([0, T+(T*pscale)])
ax.set_ylim([smin, smax])
ax.plot(t, s, color='limegreen', lw=2, label="Astrocat's trajectory")
ax.plot([t[-1]], [s[-1]], marker='o', markersize=8, color='limegreen')
ax.plot(t, m, '.', color='crimson', lw=2, label='measurements')
ax.plot([t[-1]], [m[-1]], marker='o', markersize=8, color='crimson')
ax.plot(t, filter_s_, color='black', lw=2, label='correct estimated trajectory')
ax.plot([t[-1]], [filter_s_[-1]], marker='o', markersize=8, color='black')
res = '! :)' if np.mean((s_ - filter_s_)**2) < 0.1 else ' :('
ax.plot(t, s_, '--', color='lightgray', lw=2, label='your estimated trajectory' + res)
ax.plot([t[-1]], [s_[-1]], marker='o', markersize=8, color='lightgray')
plt.legend()
plt.show()セクション1: アストロキャットの動力学
# @title Video 1: Astrocat through time
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'P1jFKXDzAYQ'), ('Bilibili', 'BV1hP4y147EC')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Astrocat_through_time_Video")# @title Video 2: Quantifying Astrocat dynamics
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', '6H8M2oE5ij8'), ('Bilibili', 'BV1sv411E777')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Quantifying_Astrocat_dynamics_Video")セクション1.1: アストロキャットの動きをシミュレートする
コーディング演習1.1: アストロキャットの動きをシミュレートする
まず、確率的線形動力学に基づいてアストロキャットの動きをシミュレートします。
線形動的システム はアストロキャットの位置 を決定します。 はアストロキャットが時間とともに位置をどのように変えたいかを表すスカラーで、 は推進ユニットの信頼性の低いアクチュエータによる白色ガウスノイズです。
以下のコードを完成させて、可能な軌跡をシミュレートしてください。
まず、以下のセルを実行して、本チュートリアルで使用するデフォルトパラメータを有効にします。
# Fixed params
np.random.seed(0)
T_max = 200
D = 1
tau_min = 1
tau_max = 50
process_noise_min = 0.1
process_noise_max = 10
measurement_noise_min = 0.1
measurement_noise_max = 10
unit_process_noise = np.random.randn(T_max) # compute all N(0, 1) in advance to speed up time slider
unit_measurement_noise = np.random.randn(T_max) # compute all N(0, 1) in advance to speed up time sliderdef simulate(D, s0, sigma_p, T):
""" Compute the response of the linear dynamical system.
Args:
D (scalar): dynamics multiplier
s0 (scalar): initial position
sigma_p (scalar): amount of noise in the system (standard deviation)
T (scalar): total duration of the simulation
Returns:
ndarray: `s`: astrocat's trajectory up to time T
"""
# Initialize variables
s = np.zeros(T+1)
s[0] = s0
# Compute the position at time t given the position at time t-1 for all t
# Consider that np.random.normal(mu, sigma) generates a random sample from
# a gaussian with mean = mu and standard deviation = sigma
for t in range(1, len(s)):
###################################################################
## Fill out the following then remove
raise NotImplementedError("Student exercise: need to implement simulation")
###################################################################
# Update position
s[t] = ...
return s
# Set random seed
np.random.seed(0)
# Set parameters
D = 0.9 # parameter in s(t)
T = 50 # total time duration
s0 = 5. # initial condition of s at time 0
sigma_p = 2 # amount of noise in the actuators of astrocat's propulsion unit
# Simulate Astrocat
s = simulate(D, s0, sigma_p, T)
# Visualize
visualize_Astrocat(s, T)出力例:
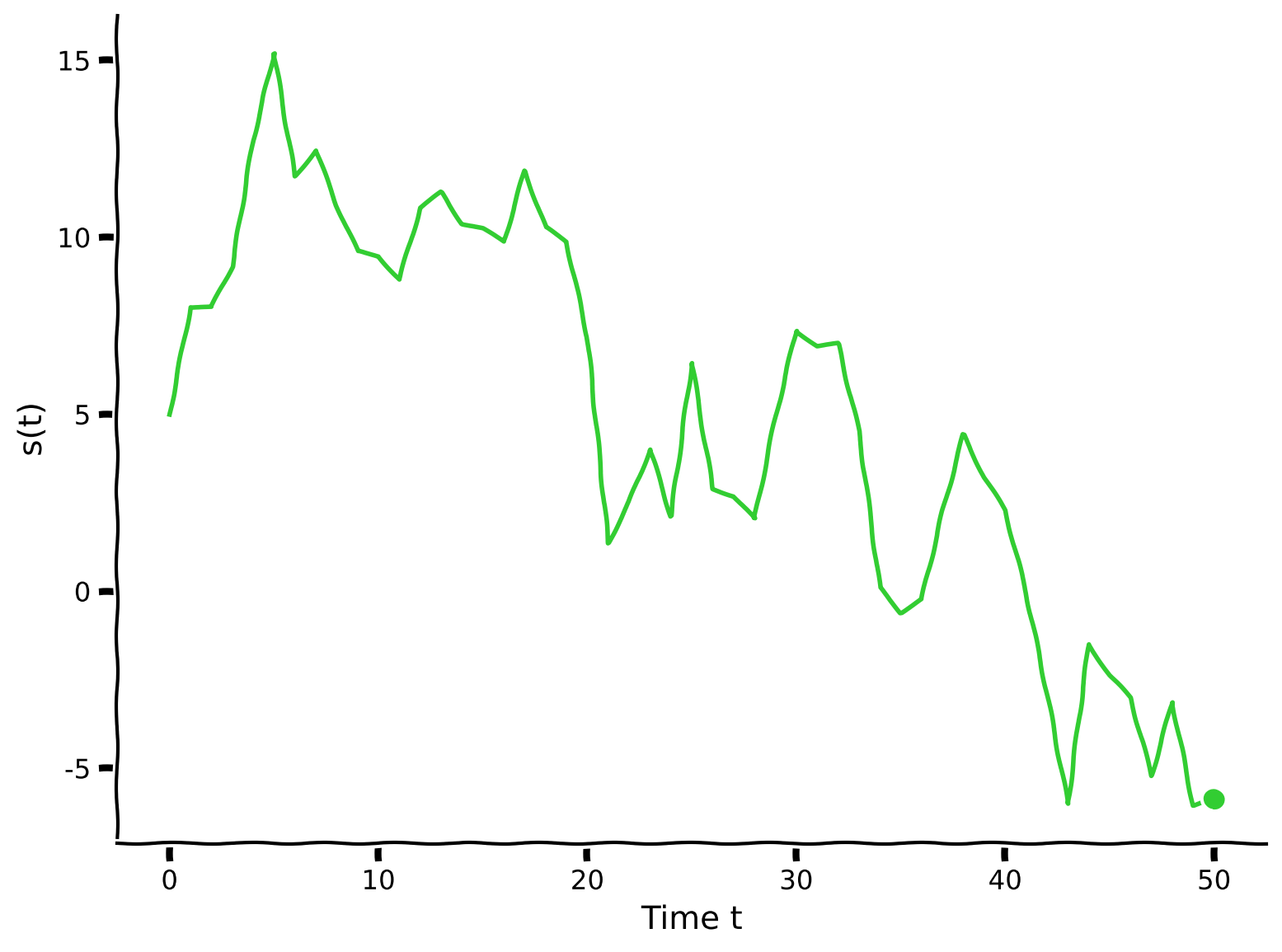
# @title Submit your feedback
content_review(f"{feedback_prefix}_Simulating_Astrocats_movements_Exercise")インタラクティブデモ 1.1: Astrocatの動きを操作してみよう
先ほど実装した関数を使って、 の値を変えて何が起こるかを見てみるデモを行います。
- が大きい場合(>1)はどうなりますか?なぜでしょう?
- が大きな負の数(<-1)の場合はどうなりますか?なぜでしょう?
- がゼロの場合はどうでしょう?
# @markdown Execute this cell to enable the demo
@widgets.interact(D=widgets.FloatSlider(value=-.5, min=-2, max=2, step=0.1))
def plot(D=D):
# Set parameters
T = 50 # total time duration
s0 = 5. # initial condition of s at time 0
sigma_p = 2 # amount of noise in the actuators of astrocat's propulsion unit
# Simulate Astrocat
s = simulate(D, s0, sigma_p, T)
# Visualize
visualize_Astrocat(s, T)# @title Submit your feedback
content_review(f"{feedback_prefix}_Playing_with_Astrocat_movement_Interactive_Demo_and_Discussion")# @title Video 3: Exercise 1.1 Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'hxnffxb1O3M'), ('Bilibili', 'BV1RU4y1n7Rh')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Exercise_1.1_Discussion_Video")セクション 1.2: Astrocatの動きを測定する
チュートリアル開始からここまでの推定所要時間:10分
# @title Video 4: Reading measurements from Astrocat's collar
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', '2csLl3R3NoU'), ('Bilibili', 'BV1Xy4y1L7fh')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Measuring_Astrocats_movements_Video")コーディング演習 1.2.1: Astrocatの首輪から測定値を読み取る
Astrocatの首輪に取り付けられたノイズのあるセンサーの測定値を使って、Astrocatの実際の位置を推定します。
以下の関数を完成させて、Astrocatの首輪から測定値を読み取ってください。これらの測定値は、入力引数 sigma_measurements で与えられる標準偏差の加法的ガウスノイズを除けば正確です。
def read_collar(s, sigma_measurements):
""" Compute the measurements of the noisy sensor attached to astrocat's collar
Args:
s (ndarray): astrocat's true position over time
sigma_measurements (scalar): amount of noise in the sensor (standard deviation)
Returns:
ndarray: `m`: astrocat's position over time according to the sensor
"""
# Initialize variables
m = np.zeros(len(s))
# For all time t, add white Gaussian noise with magnitude sigma_measurements
# Consider that np.random.normal(mu, sigma) generates a random sample from
# a gaussian with mean = mu and standard deviation = sigma
for t in range(len(s)):
###################################################################
## Fill out the following then remove
raise NotImplementedError("Student exercise: need to implement read_collar function")
###################################################################
# Read measurement
m[t] = ...
return m
# Set parameters
np.random.seed(0)
D = 0.9 # parameter in s(t)
T = 50 # total time duration
s0 = 5. # initial condition of s at time 0
sigma_p = 2 # amount of noise in the actuators of astrocat's propulsion unit
sigma_measurements = 4 # amount of noise in astrocat's collar
# Simulate Astrocat
s = simulate(D, s0, sigma_p, T)
# Take measurement from collar
m = read_collar(s, sigma_measurements)
# Visualize
plot_measurement(s, m, T)出力例:
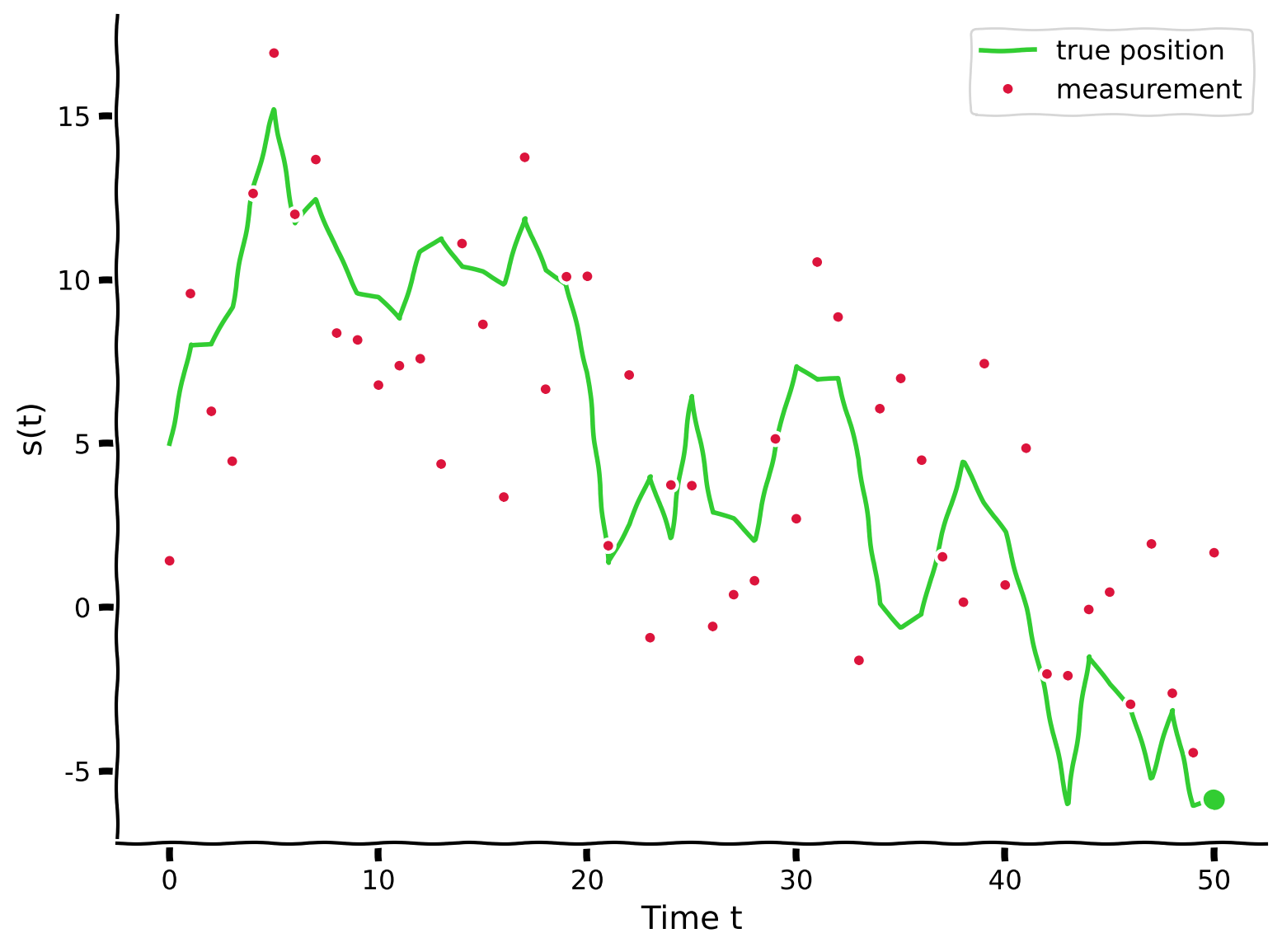
# @title Submit your feedback
content_review(f"{feedback_prefix}_Reading_measurements_from_Astrocats_collar_Exercise")# @title Video 5: Exercise 1.2.1 Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'O0Sxu5mtsqY'), ('Bilibili', 'BV1y44y1274K')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Exercise_1.2.1_Discussion_Video")# @title Video 6: Comparing true states to measured states
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'BulWhzSPhmQ'), ('Bilibili', 'BV1Jf4y157sv')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Comparing_true_states_to_measured_states_Video")コーディング演習 1.2.2: 真の状態と測定状態を比較する
Astrocatの首輪の測定値がどれほど悪いかを散布図で確認しましょう。この演習は、測定値だけを使ってAstrocatを追跡することがいかに問題になるかを示します。
この問題はカルマンフィルターで解決できます!
def compare(s, m):
""" Compute a scatter plot
Args:
s (ndarray): astrocat's true position over time
m (ndarray): astrocat's measured position over time according to the sensor
"""
###################################################################
## Fill out the following then remove
raise NotImplementedError("Student exercise: need to implement compare function")
###################################################################
fig = plt.figure()
ax = fig.add_subplot(111)
sbounds = 1.1*max(max(np.abs(s)), max(np.abs(m)))
ax.plot([-sbounds, sbounds], [-sbounds, sbounds], 'k') # plot line of equality
ax.set_xlabel('state')
ax.set_ylabel('measurement')
ax.set_aspect('equal')
# Complete a scatter plot: true state versus measurements
...
plt.show()
# Set parameters
np.random.seed(0)
D = 0.9 # parameter in s(t)
T = 50 # total time duration
s0 = 5. # initial condition of s at time 0
sigma_p = 2 # amount of noise in the actuators of astrocat's propulsion unit
sigma_measurements = 4 # amount of noise in astrocat's collar
# Simulate Astrocat
s = simulate(D, s0, sigma_p, T)
# Take measurement from collar
m = read_collar(s, sigma_measurements)
# Visualize true vs measured states
compare(s, m)出力例:
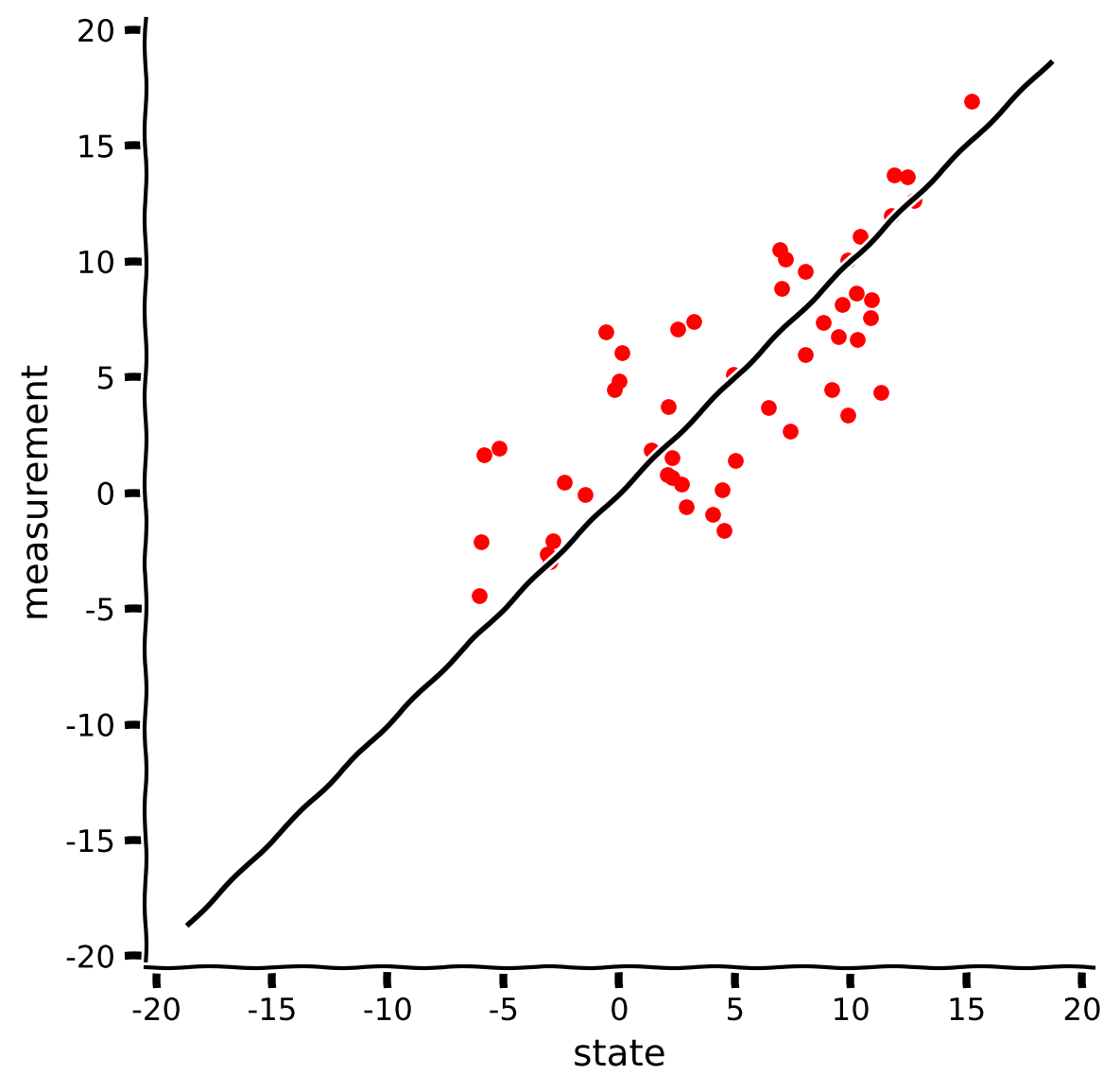
# @title Submit your feedback
content_review(f"{feedback_prefix}_Compare_true_states_to_measured_states_Exercise")# @title Video 7: Exercise 1.2.2 Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'pOa8PdXa60s'), ('Bilibili', 'BV1Mg411M7m6')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Exercise_1.2.2_Discussion_Video")セクション 2: カルマンフィルター
セクション 2.1: カルマンフィルターの使用法
チュートリアル開始からここまでの推定所要時間: 20分
# @title Video 8: The Kalman filter
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', '4fjCv9FKHYI'), ('Bilibili', 'BV1bP4y147ud')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_The_Kalman_filter_Video")インタラクティブデモ 2.1: カルマンフィルターの動作
次に、カルマンフィルターの仕組みを理解するためのインタラクティブな可視化を提供します。スライダーを操作して、さまざまな要素がカルマンフィルターの推定にどのように影響するかを直感的に掴んでください。次の演習でカルマンフィルターを自分でコーディングします。
スライダーの説明:
- 現在時刻: カルマンフィルターはこの時刻までの測定値を統合します。
- 動的時定数 : これは動的値 を決定します。ここで は離散時間ステップ(ここでは1)です。
- プロセスノイズ: アストロキャットの推進装置のアクチュエータにおけるノイズの量
- 観測ノイズ: 測定値(首輪の読み取り時)のノイズレベル
考慮すべき質問:
- アストロキャットの予測可能性に影響を与えるのは何か?
- 時間経過とともに信頼度はどう変わるか?
- 新しい測定値の相対的重みは何に影響されるか?
- 誤差は事後分散とどのように関連しているか?
# @markdown Execute this cell to enable the widget. It takes a few seconds to update so please be patient.
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(T=widgets.IntSlider(T_max/4, description="current time",
min=1, max=T_max-1),
tau=widgets.FloatSlider(tau_max/2,
description='dynamics time constant',
min=tau_min, max=tau_max),
process_noise=widgets.FloatSlider(2,
description="process noise",
min=process_noise_min,
max=process_noise_max),
measurement_noise=widgets.FloatSlider(3,
description="observation noise",
min=measurement_noise_min,
max=measurement_noise_max),
flag_s = widgets.Checkbox(value=True,
description='state',
disabled=True, indent=False),
flag_m = widgets.Checkbox(value=False,
description='measurement',
disabled=False, indent=False),
flag_s_ = widgets.Checkbox(value=False,
description='estimate',
disabled=False, indent=False),
flag_err_ = widgets.Checkbox(value=False,
description='estimator confidence intervals',
disabled=False, indent=False))
def stochastic_system(T, tau, process_noise, measurement_noise, flag_m, flag_s_, flag_err_):
t = np.arange(0, T_max, 1) # timeline
s = np.zeros(T_max) # states
D = np.exp(-1/tau) # dynamics multiplier (matrix if s is vector)
process_noise_cov = process_noise**2
measurement_noise_cov = measurement_noise**2
prior_mean = 0
prior_cov = process_noise_cov/(1-D**2)
s[0] = np.sqrt(prior_cov) * unit_process_noise[0] # Sample initial condition from equilibrium distribution
m = np.zeros(T_max) # measurement
s_ = np.zeros(T_max) # estimate (posterior mean)
cov_ = np.zeros(T_max) # uncertainty (posterior covariance)
s_[0] = prior_mean
cov_[0] = prior_cov
posterior = gaussian(prior_mean, prior_cov)
captured_prior = None
captured_likelihood = None
captured_posterior = None
onfilter = True
for i in range(1, T_max):
s[i] = D * s[i-1] + process_noise * unit_process_noise[i-1]
if onfilter:
m[i] = s[i] + measurement_noise * unit_measurement_noise[i]
prior, likelihood, posterior = filter(D, process_noise_cov, measurement_noise_cov, posterior, m[i])
s_[i] = posterior.mean
cov_[i] = posterior.cov
if i == T:
onfilter = False
captured_prior = prior
captured_likelihood = likelihood
captured_posterior = posterior
smin = min(min(m),min(s-2*np.sqrt(cov_[-1])),min(s_-2*np.sqrt(cov_[-1])))
smax = max(max(m),max(s+2*np.sqrt(cov_[-1])),max(s_+2*np.sqrt(cov_[-1])))
pscale = 0.2 # scaling factor for displaying pdfs
fig = plt.figure(figsize=[15, 10])
ax = plt.subplot(2, 1, 1)
ax.set_xlabel('time')
ax.set_ylabel('state')
ax.set_xlim([0, T_max+(T_max*pscale)])
ax.set_ylim([smin, smax])
show_pdf = [False, False]
ax.plot(t[:T+1], s[:T+1], color='limegreen', lw=2)
ax.plot(t[T:], s[T:], color='limegreen', lw=2, alpha=0.3)
ax.plot([t[T:T+1]], [s[T:T+1]], marker='o', markersize=8, color='limegreen')
if flag_m:
ax.plot(t[:T+1], m[:T+1], '.', color='crimson', lw=2)
ax.plot([t[T:T+1]], [m[T:T+1]], marker='o', markersize=8, color='crimson')
domain = np.linspace(ax.get_ylim()[0], ax.get_ylim()[1], 500)
pdf_likelihood = norm.pdf(domain, captured_likelihood.mean, np.sqrt(captured_likelihood.cov))
ax.fill_betweenx(domain, T + pdf_likelihood*(T_max*pscale), T, color='crimson', alpha=0.5, label='likelihood', edgecolor="crimson", linewidth=0)
ax.plot(T + pdf_likelihood*(T_max*pscale), domain, color='crimson', linewidth=2.0)
ax.legend(ncol=3, loc='upper left')
show_pdf[0] = True
if flag_s_:
ax.plot(t[:T+1], s_[:T+1], color='black', lw=2)
ax.plot([t[T:T+1]], [s_[T:T+1]], marker='o', markersize=8, color='black')
show_pdf[1] = True
if flag_err_:
ax.fill_between(t[:T+1], s_[:T+1] + 2 * np.sqrt(cov_)[:T+1], s_[:T+1] - 2 * np.sqrt(cov_)[:T+1], color='black', alpha=0.3)
show_pdf[1] = True
if show_pdf[1]:
domain = np.linspace(ax.get_ylim()[0], ax.get_ylim()[1], 500)
pdf_post = norm.pdf(domain, captured_posterior.mean, np.sqrt(captured_posterior.cov))
ax.fill_betweenx(domain, T + pdf_post*(T_max*pscale), T, color='black', alpha=0.5, label='posterior', edgecolor="black", linewidth=0)
ax.plot(T + pdf_post*(T_max*pscale), domain, color='black', linewidth=2.0)
ax.legend(ncol=3, loc='upper left')
if show_pdf[0] and show_pdf[1]:
domain = np.linspace(ax.get_ylim()[0], ax.get_ylim()[1], 500)
pdf_prior = norm.pdf(domain, captured_prior.mean, np.sqrt(captured_prior.cov))
ax.fill_betweenx(domain, T + pdf_prior*(T_max*pscale), T, color='dodgerblue', alpha=0.5, label='prior', edgecolor="dodgerblue", linewidth=0)
ax.plot(T + pdf_prior*(T_max*pscale), domain, color='dodgerblue', linewidth=2.0)
ax.legend(ncol=3, loc='upper left')
plt.show()# @title Submit your feedback
content_review(f"{feedback_prefix}_The_Kalman_filter_in_action_Interactive_Demo")# @title Video 9: Interactive Demo 2.1 Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'Vif-dLc5ilE'), ('Bilibili', 'BV1ko4y1D78w')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Interactive_Demo_2.1_Discussion_Video")# @title Video 10: Implementing a Kalman filter
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'aTy1ScpTGHU'), ('Bilibili', 'BV1Gy4y1j7YY')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Implementing_a_Kalman_filter_Video")コーディング演習 2.1: 自分でカルマンフィルターを実装しよう
ビデオと前の演習で見たように、カルマンフィルターはプロセスの数学モデルと入ってくる測定値を用いて、時系列に沿って再帰的に事後確率分布を推定します。この動的な事後分布により、新しい測定値が到着するたびにアストロキャットの位置に関する推定を改善できます。さらに、その平均は各時刻におけるアストロキャットの実際の位置の最良推定値となります。
さあ、あなたの番です!以下の手順に従ってコードを完成させ、自分のカルマンフィルターを実装してください。
ステップ1: 昨日の事後分布を今日の事前分布に変換する
数学モデルを使って、プロセスの決定論的変化が昨日の事後分布 をどのようにシフトさせるか、またプロセスのランダムな変化がシフトした分布をどのように広げるかを計算します:
ここでプロセスノイズは と表記していますが、ビデオでは を使っていました(前節と合わせるための表記変更です)。
ステップ2: 今日の事前分布に尤度を掛ける
アストロキャットの首輪の最新測定値(新しい証拠)を使って、ステップ1で予測した値とこの測定値の間のどこかに新しい推定値を形成します。次の事後分布は、ステップ1で計算したガウス分布(今日の事前分布)と尤度(これもガウス分布 )の積の結果です。
2a: 事前分布と尤度の情報を足す
事後分散を求めるには、まず事後情報量(分散の逆数)を、事前分布と尤度が提供する情報量の和として計算します:
これで事後情報量の逆数を取ることで事後分散を得られます。
2b: 事前分布と尤度の平均を足す
事後平均を求めるには、事前分布と尤度の平均の重み付き平均を計算します。ここで各重み は、それぞれのガウス分布が提供する情報量の割合です。
\begin{align}
g_{\rm{prior}} &= \
g_{\rm{likelihood}} &= \
&= g_{\rm{prior}} D\mu_{s_{t-1}} + g_{\rm{likelihood}} m_t \end{align}
おめでとうございます!
実装の詳細: ガウス分布の統計量には、例えば以下のようにアクセスできます。
prior.mean
prior.cov
オプション: 古典的なカルマンフィルターの記述との関係:
この手順を教えているのは解釈しやすく、ガウス分布の和則・積則の過去のレッスンとつながるからです。しかし古典的なカルマンフィルターの記述は少し異なります。上記の重み と は合計で1になり、片方をもう一方の式で表せます。ここで とすると、事後平均は以下のように表現できます:
古典的な教科書ではこの式がよく見られます。 はカルマンゲインと呼ばれ、その役割は現在の測定値 とステップ1の予測値の間の値を選ぶことです。
# Set random seed
np.random.seed(0)
# Set parameters
T = 50 # Time duration
tau = 25 # dynamics time constant
process_noise = 2 # process noise in Astrocat's propulsion unit (standard deviation)
measurement_noise = 9 # measurement noise in Astrocat's collar (standard deviation)
# Auxiliary variables
process_noise_cov = process_noise**2 # process noise in Astrocat's propulsion unit (variance)
measurement_noise_cov = measurement_noise**2 # measurement noise in Astrocat's collar (variance)
# Initialize arrays
t = np.arange(0, T, 1) # timeline
s = np.zeros(T) # states
D = np.exp(-1/tau) # dynamics multiplier (matrix if s is vector)
m = np.zeros(T) # measurement
s_ = np.zeros(T) # estimate (posterior mean)
cov_ = np.zeros(T) # uncertainty (posterior covariance)
# Initial guess of the posterior at time 0
initial_guess = gaussian(0, process_noise_cov/(1-D**2)) # In this case, the initial guess (posterior distribution
# at time 0) is the equilibrium distribution, but feel free to
# experiment with other gaussians
posterior = initial_guess
# Sample initial conditions
s[0] = posterior.mean + np.sqrt(posterior.cov) * np.random.randn() # Sample initial condition from posterior distribution at time 0
s_[0] = posterior.mean
cov_[0] = posterior.cov
# Loop over steps
for i in range(1, T):
# Sample true states and corresponding measurements
s[i] = D * s[i-1] + np.random.normal(0, process_noise) # variable `s` records the true position of Astrocat
m[i] = s[i] + np.random.normal(0, measurement_noise) # variable `m` records the measurements of Astrocat's collar
###################################################################
## Fill out the following then remove
raise NotImplementedError("Student exercise: need to implement the Kalman filter")
###################################################################
# Step 1. Shift yesterday's posterior to match the deterministic change of the system's dynamics,
# and broad it to account for the random change (i.e., add mean and variance of process noise).
todays_prior = ...
# Step 2. Now that yesterday's posterior has become today's prior, integrate new evidence
# (i.e., multiply gaussians from today's prior and likelihood)
likelihood = ...
# Step 2a: To find the posterior variance, add information (inverse variances) of prior and likelihood
info_prior = 1/todays_prior.cov
info_likelihood = 1/likelihood.cov
info_posterior = ...
# Step 2b: To find the posterior mean, calculate a weighted average of means from prior and likelihood;
# the weights are just the fraction of information that each gaussian provides!
prior_weight = info_prior / info_posterior
likelihood_weight = info_likelihood / info_posterior
posterior_mean = ...
# Don't forget to convert back posterior information to posterior variance!
posterior_cov = 1/info_posterior
posterior = gaussian(posterior_mean, posterior_cov)
s_[i] = posterior.mean
cov_[i] = posterior.cov
# Visualize
paintMyFilter(D, initial_guess, process_noise_cov, measurement_noise_cov, s, m, s_, cov_)出力例:
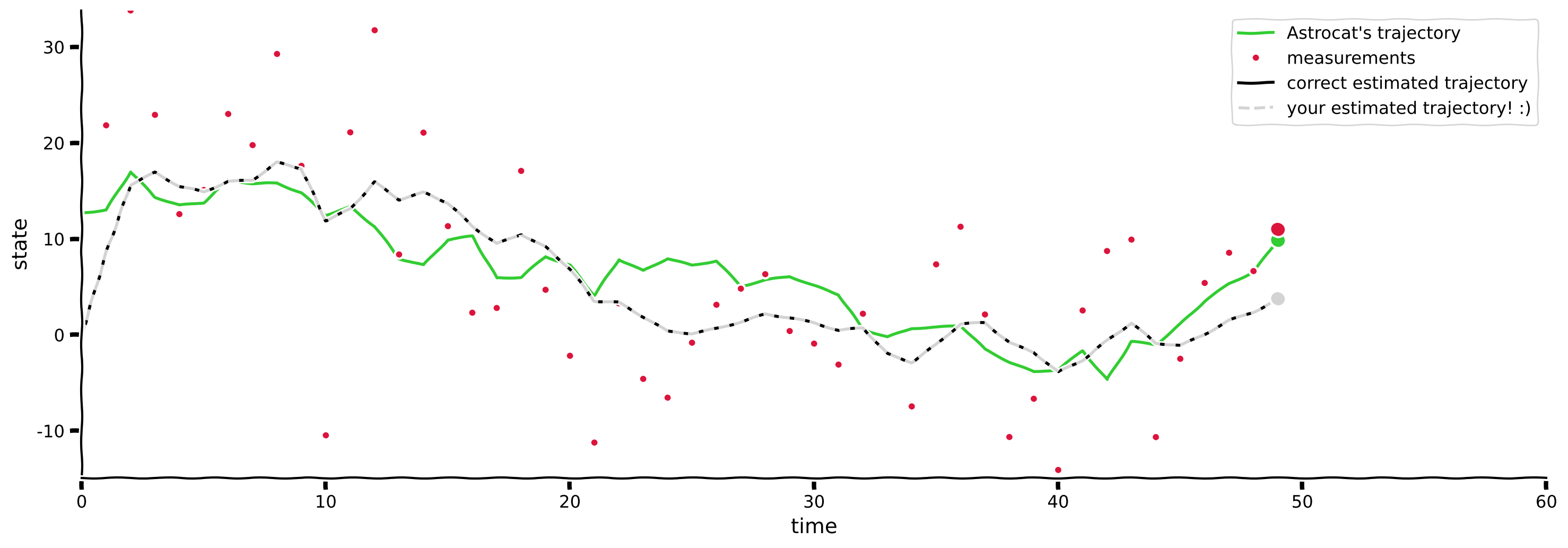
# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_your_own_Kalman_filter_Exercise")# @title Video 11: Exercise 2.1 Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'mmiwlenUiMo'), ('Bilibili', 'BV1xg411M7Gy')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Exercise_2.1_Discussion_Video")セクション 2.2: 推定精度
チュートリアル開始からここまでの推定所要時間: 50分
# @title Video 12: Compare states, estimates, and measurements
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'AZUObJuc5Bw'), ('Bilibili', 'BV1Fy4y1j75Z')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Compare_states_estimates_and_measurements_Video")インタラクティブデモ 2.2: 状態、推定値、測定値の比較
推定値 は実際の値 とどの程度一致しているでしょうか?誤差の分布 は事後分散とどのように比較されますか?なぜでしょう?隠れマルコフモデルのパラメータを変えて、その性質がどのように変わるか観察してみてください。
また、測定値 は真の状態とどのように比較されるでしょうか?
# @markdown Execute cell to enable the demo
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(tau=widgets.FloatSlider(tau_max/2, description='tau',
min=tau_min, max=tau_max),
process_noise=widgets.FloatSlider(2,
description="process noise",
min=process_noise_min,
max=process_noise_max),
measurement_noise=widgets.FloatSlider(3,
description="observation noise",
min=measurement_noise_min,
max=measurement_noise_max),
flag_m = widgets.Checkbox(value=False,
description='measurements',
disabled=False, indent=False))
def stochastic_system(tau, process_noise, measurement_noise, flag_m):
T = T_max
t = np.arange(0, T_max, 1) # timeline
s = np.zeros(T_max) # states
D = np.exp(-1/tau) # dynamics multiplier (matrix if s is vector)
process_noise_cov = process_noise**2 # process noise in Astrocat's propulsion unit (variance)
measurement_noise_cov = measurement_noise**2 # measurement noise in Astrocat's collar (variance)
prior_mean = 0
prior_cov = process_noise_cov/(1-D**2)
s[0] = np.sqrt(prior_cov) * np.random.randn() # Sample initial condition from equilibrium distribution
m = np.zeros(T_max) # measurement
s_ = np.zeros(T_max) # estimate (posterior mean)
cov_ = np.zeros(T_max) # uncertainty (posterior covariance)
s_[0] = prior_mean
cov_[0] = prior_cov
posterior = gaussian(prior_mean, prior_cov)
for i in range(1, T):
s[i] = D * s[i-1] + process_noise * np.random.randn()
m[i] = s[i] + measurement_noise * np.random.randn()
prior, likelihood, posterior = filter(D, process_noise_cov,
measurement_noise_cov,
posterior, m[i])
s_[i] = posterior.mean
cov_[i] = posterior.cov
fig = plt.figure(figsize=[10, 5])
ax = plt.subplot(1, 2, 1)
ax.set_xlabel('s')
ax.set_ylabel('$\mu$')
sbounds = 1.1*max(max(np.abs(s)), max(np.abs(s_)), max(np.abs(m)))
ax.plot([-sbounds, sbounds], [-sbounds, sbounds], 'k') # plot line of equality
ax.errorbar(s, s_, yerr=2*np.sqrt(cov_[-1]), marker='.',
mfc='black', mec='black', linestyle='none', color='gray')
axhist = plt.subplot(1, 2, 2)
axhist.set_xlabel('error $s-\hat{s}$')
axhist.set_ylabel('probability')
axhist.hist(s-s_, density=True, bins=25, alpha=.5,
label='histogram of estimate errors', color='yellow')
if flag_m:
ax.plot(s, m, marker='.', linestyle='none', color='red')
axhist.hist(s - m, density=True, bins=25, alpha=.5,
label='histogram of measurement errors', color='orange')
domain = np.arange(-sbounds, sbounds, 0.1)
pdf_g = norm.pdf(domain, 0, np.sqrt(cov_[-1]))
axhist.fill_between(domain, pdf_g, color='black',
alpha=0.5, label='posterior shifted to mean')
axhist.legend()
plt.show()# @title Submit your feedback
content_review(f"{feedback_prefix}_Compare_states_estimates_and_measurements_Interactive_Demo")# @title Video 13: Interactive Demo 2.2 Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'nK46HBTy4Y8'), ('Bilibili', 'BV1EU4y1n7ew')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Interactive_Demo_2.2_Discussion_Video")セクション 2.3: アストロキャットの探索
チュートリアル開始からここまでの推定所要時間: 1時間
# @title Video 14: How long does it take to find astrocat?
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', '4prm8bZr4no'), ('Bilibili', 'BV1AX4y1c72s')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_How_long_does_it_take_to_find_astrocat_Video")インタラクティブデモ 2.3: アストロキャットを見つけるのにどれくらいかかる?
ここでは時間の関数として事後分散をプロットします。ミッションコントロールが測定値を得る前は、アストロキャットの位置に関する唯一の情報は事前分布です。いくつかの測定値を得た後、彼らはアストロキャットの位置を絞り込みます。
- 分散は時間とともにどのように縮小するでしょうか?
- 速度はプロセスの動的特性に依存しますが、信号対雑音比(SNR)にも依存するでしょうか?(ここでのSNRはデシベル単位の対数スケールで、1 dBは0.1の対数単位を意味します。)
赤い曲線は初期条件から指数関数的に潜在分散が平衡に達する速さを示しており、時定数は です。(注: 視覚的に事後平衡分散と合わせるために曲線をシフト・スケーリングしています。これにより時間スケールの比較がしやすくなっています。)潜在プロセスは事後分布より速く収束するでしょうか、それとも遅いでしょうか?カルマンフィルターが証拠を統合する仕組みから説明できますか?
# @markdown Execute this cell to enable the demo
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(T=widgets.IntSlider(tau_max, description="max time",
min=2, max=T_max-1),
tau=widgets.FloatSlider(tau_max/2,
description='time constant',
min=tau_min, max=tau_max),
SNRdB=widgets.FloatSlider(-20.,
description="SNR (decibels)",
min=-40., max=10.))
def stochastic_system(T, tau, SNRdB):
t = np.arange(0, T, 1) # timeline
s = np.zeros(T) # states
D = np.exp(-1/tau) # dynamics matrix (scalar here)
prior_mean = 0
process_noise = 1
SNR = 10**(.1*SNRdB)
measurement_noise = process_noise / SNR
prior_cov = process_noise/(1-D**2)
s[0] = np.sqrt(prior_cov) * unit_process_noise[0] # Sample initial condition from equilibrium distribution
m = np.zeros(T) # measurements
s_ = np.zeros(T) # estimates (posterior mean)
cov_ = np.zeros(T) # uncertainty (posterior covariance)
pcov = np.zeros(T) # process covariance
s_[0] = prior_mean
cov_[0] = prior_cov
posterior = gaussian(prior_mean, prior_cov)
for i in range(1, T):
s[i] = D * s[i-1] + np.sqrt(process_noise) * unit_process_noise[i-1]
m[i] = s[i] + np.sqrt(measurement_noise) * unit_measurement_noise[i]
prior, likelihood, posterior = filter(D, process_noise,
measurement_noise, posterior, m[i])
s_[i] = posterior.mean
cov_[i] = posterior.cov
pcov[i] = D**2 * pcov[i-1] + process_noise
equilibrium_posterior_var = process_noise * (D**2 - 1 - SNR + np.sqrt((D**2 - 1 - SNR)**2 + 4 * D**2 * SNR)) / (2 * D**2 * SNR)
equilibrium_process_var = process_noise / (1-D**2)
scale = (max(cov_) - equilibrium_posterior_var) / equilibrium_process_var
pcov = pcov * scale # scale for better visual comparison of temporal structure
fig, ax = plt.subplots()
ax.set_xlabel('time')
ax.set_xlim([0, T])
ax.fill_between(t, 0, cov_, color='black', alpha=0.3)
ax.plot(t, cov_, color='black', label='posterior variance')
ax.set_ylabel('posterior variance')
ax.set_ylim([0, max(cov_)])
ax2 = ax.twinx() # instantiate a second axes that shares the same x-axis
ax2.fill_between(t, min(pcov), pcov, color='red', alpha=0.3)
ax2.plot(t, pcov, color='red', label='hidden process variance')
ax2.set_ylabel('hidden process variance (scaled)', color='red',
rotation=-90, labelpad=20)
ax2.tick_params(axis='y', labelcolor='red')
# ax2.yaxis.set_major_formatter(plt.FuncFormatter(format_func))
ax2.set_yticks([0, equilibrium_process_var - equilibrium_posterior_var])
ax2.set_yticklabels(['0', 'equilibrium\nprocess var'])
ax2.set_ylim([max(cov_), 0])
fig.tight_layout() # otherwise the right y-label is slightly clipped
plt.show()# @title Submit your feedback
content_review(f"{feedback_prefix}_How_long_does_it_take_to_find_astrocat_Interactive_Demo")# @title Video 15: Interactive Demo 2.3 Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'AYOkyKnfPNM'), ('Bilibili', 'BV1ng411M7N5')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Interactive_Demo_2.3_Discussion_Video")脳科学におけるカルマンフィルターの応用例
- 脳-コンピュータ・インターフェース: 神経活動を測定値として意図した動きを推定する。
- データ解析: ノイズの多い測定(例: EEG)から脳活動を推定する。
- 知覚のモデル: ノイズのある感覚測定を使った獲物追跡。
- あなた自身の例を想像してみてください!直接見えないものを推定しようとしているのはどんな時ですか?
カルマンフィルターの制限を克服する多くのバリエーションがあります:非ガウス状態と測定、非線形動力学など。
まとめ
チュートリアルの推定所要時間: 1時間15分
このチュートリアルでは、
- 1次元連続線形動的システムをシミュレートし、隠れ状態のノイズのある測定を行い
- カルマンフィルターを使ってノイズのある測定だけを使うよりも正確に隠れ状態を復元し、これをベイズ的な考え方と結びつけ
- プロセスのパラメータを操作してカルマンフィルターの挙動をより深く理解しました