![]()

チュートリアル 1: 二値の隠れ状態を用いたベイズ推定
第3週、第2日目:ベイズ的意思決定
Neuromatch Academy 提供
コンテンツ作成者: Eric DeWitt, Xaq Pitkow, Ella Batty, Saeed Salehi
コンテンツレビュアー: Hyosub Kim, Zahra Arjmandi, Anoop Kulkarni
制作編集者: Ella Batty, Gagana B, Spiros Chavlis
チュートリアルの目的
チュートリアルの推定所要時間:1時間30分
これはベイズ統計に関する2つのコアチュートリアルのうちの最初です。このチュートリアルでは、ベイズ的アプローチの基本概念を探求します。このチュートリアルでは、二値の隠れ状態を用いたベイズ推論と意思決定の例を通して学びます。2つ目のチュートリアルでは、これらの概念を連続的な隠れ状態に拡張します。関連するNMAの日程では、これらの基本的なアイデアがさらに発展します。Hidden Dynamicsでは、繰り返しの観測を用いて隠れ状態を推論するときや、隠れ状態が時間とともに変化するときに何が起こるかを時間軸で考察します。Optimal Controlの日には、推論と意思決定を用いて最適制御のための行動を選択する方法を紹介します。
このノートブックでは、ベイズ統計の基本的な構成要素を紹介します:
- 意思決定における可能な損失(または利益)を確率的知識とどのように組み合わせるか?
- 隠れ状態を表現するために確率分布をどのように使うか?
- 周辺化(マージナライゼーション)はどのように機能し、どのように利用できるか?
- 新しい情報を事前知識とどのように組み合わせるか?
# @title Tutorial slides
# @markdown These are the slides for the videos in this tutorial
from IPython.display import IFrame
link_id = "dx7jt"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)セットアップ
# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W3D1_T1"# Imports
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import patches, transforms, gridspec
from scipy.optimize import fsolve
from collections import namedtuple# @title Figure Settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
import ipywidgets as widgets # interactive display
from ipywidgets import GridspecLayout, HBox, VBox, FloatSlider, Layout, ToggleButtons
from ipywidgets import interactive, interactive_output, Checkbox, Select
from IPython.display import clear_output
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")
import warnings
warnings.filterwarnings("ignore")# @title Plotting Functions
from matplotlib import colors
def plot_joint_probs(P, ):
assert np.all(P >= 0), "probabilities should be >= 0"
# normalize if not
P = P / np.sum(P)
marginal_y = np.sum(P,axis=1)
marginal_x = np.sum(P,axis=0)
# definitions for the axes
left, width = 0.1, 0.65
bottom, height = 0.1, 0.65
spacing = 0.005
# start with a square Figure
fig = plt.figure(figsize=(5, 5))
joint_prob = [left, bottom, width, height]
rect_histx = [left, bottom + height + spacing, width, 0.2]
rect_histy = [left + width + spacing, bottom, 0.2, height]
rect_x_cmap = plt.cm.Blues
rect_y_cmap = plt.cm.Reds
# Show joint probs and marginals
ax = fig.add_axes(joint_prob)
ax_x = fig.add_axes(rect_histx, sharex=ax)
ax_y = fig.add_axes(rect_histy, sharey=ax)
# Show joint probs and marginals
ax.matshow(P,vmin=0., vmax=1., cmap='Greys')
ax_x.bar(0, marginal_x[0], facecolor=rect_x_cmap(marginal_x[0]))
ax_x.bar(1, marginal_x[1], facecolor=rect_x_cmap(marginal_x[1]))
ax_y.barh(0, marginal_y[0], facecolor=rect_y_cmap(marginal_y[0]))
ax_y.barh(1, marginal_y[1], facecolor=rect_y_cmap(marginal_y[1]))
# set limits
ax_x.set_ylim([0, 1])
ax_y.set_xlim([0, 1])
# show values
ind = np.arange(2)
x,y = np.meshgrid(ind,ind)
for i,j in zip(x.flatten(), y.flatten()):
c = f"{P[i, j]:.2f}"
ax.text(j,i, c, va='center', ha='center', color='black')
for i in ind:
v = marginal_x[i]
c = f"{v:.2f}"
ax_x.text(i, v +0.1, c, va='center', ha='center', color='black')
v = marginal_y[i]
c = f"{v:.2f}"
ax_y.text(v+0.2, i, c, va='center', ha='center', color='black')
# set up labels
ax.xaxis.tick_bottom()
ax.yaxis.tick_left()
ax.set_xticks([0,1])
ax.set_yticks([0,1])
ax.set_xticklabels(['Silver', 'Gold'])
ax.set_yticklabels(['Small', 'Large'])
ax.set_xlabel('color')
ax.set_ylabel('size')
ax_x.axis('off')
ax_y.axis('off')
return fig
def plot_prior_likelihood_posterior(prior, likelihood, posterior):
# definitions for the axes
left, width = 0.05, 0.3
bottom, height = 0.05, 0.9
padding = 0.12
small_width = 0.1
left_space = left + small_width + padding
added_space = padding + width
fig = plt.figure(figsize=(12, 4))
rect_prior = [left, bottom, small_width, height]
rect_likelihood = [left_space , bottom , width, height]
rect_posterior = [left_space + added_space, bottom , width, height]
ax_prior = fig.add_axes(rect_prior)
ax_likelihood = fig.add_axes(rect_likelihood, sharey=ax_prior)
ax_posterior = fig.add_axes(rect_posterior, sharey = ax_prior)
rect_colormap = plt.cm.Blues
# Show posterior probs and marginals
ax_prior.barh(0, prior[0], facecolor=rect_colormap(prior[0, 0]))
ax_prior.barh(1, prior[1], facecolor=rect_colormap(prior[1, 0]))
ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')
ax_posterior.matshow(posterior, vmin=0., vmax=1., cmap='Greens')
# Probabilities plot details
ax_prior.set(xlim=[1, 0], xticks=[], yticks=[0, 1],
yticklabels=['left', 'right'], title="Prior p(s)")
ax_prior.yaxis.tick_right()
ax_prior.spines['left'].set_visible(False)
ax_prior.spines['bottom'].set_visible(False)
# Likelihood plot details
ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],
yticks=[0, 1], yticklabels=['left', 'right'],
ylabel='state (s)', xlabel='measurement (m)',
title='Likelihood p(m (left) | s)')
ax_likelihood.xaxis.set_ticks_position('bottom')
ax_likelihood.spines['left'].set_visible(False)
ax_likelihood.spines['bottom'].set_visible(False)
# Posterior plot details
ax_posterior.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],
yticks=[0, 1], yticklabels=['left', 'right'],
ylabel='state (s)', xlabel='measurement (m)',
title='Posterior p(s | m)')
ax_posterior.xaxis.set_ticks_position('bottom')
ax_posterior.spines['left'].set_visible(False)
ax_posterior.spines['bottom'].set_visible(False)
# show values
ind = np.arange(2)
x,y = np.meshgrid(ind,ind)
for i,j in zip(x.flatten(), y.flatten()):
c = f"{posterior[i, j]:.2f}"
ax_posterior.text(j, i, c, va='center', ha='center', color='black')
for i,j in zip(x.flatten(), y.flatten()):
c = f"{likelihood[i, j]:.2f}"
ax_likelihood.text(j, i, c, va='center', ha='center', color='black')
for i in ind:
v = prior[i, 0]
c = f"{v:.2f}"
ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')
def plot_prior_likelihood(ps, p_a_s1, p_a_s0, measurement):
likelihood = np.asarray([[p_a_s1, 1-p_a_s1], [p_a_s0, 1-p_a_s0]])
assert 0.0 <= ps <= 1.0
prior = np.asarray([ps, 1 - ps])
if measurement == "Fish":
posterior = likelihood[:, 0] * prior
else:
posterior = (likelihood[:, 1] * prior).reshape(-1)
posterior /= np.sum(posterior)
# definitions for the axes
left, width = 0.05, 0.3
bottom, height = 0.05, 0.9
padding = 0.12
small_width = 0.2
left_space = left + small_width + padding
small_padding = 0.05
fig = plt.figure(figsize=(12, 4))
rect_prior = [left, bottom, small_width, height]
rect_likelihood = [left_space , bottom , width, height]
rect_posterior = [left_space + width + small_padding, bottom , small_width, height]
ax_prior = fig.add_axes(rect_prior)
ax_likelihood = fig.add_axes(rect_likelihood, sharey=ax_prior)
ax_posterior = fig.add_axes(rect_posterior, sharey=ax_prior)
prior_colormap = plt.cm.Blues
posterior_colormap = plt.cm.Greens
# Show posterior probs and marginals
ax_prior.barh(0, prior[0], facecolor=prior_colormap(prior[0]))
ax_prior.barh(1, prior[1], facecolor=prior_colormap(prior[1]))
ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')
ax_posterior.barh(0, posterior[0], facecolor=posterior_colormap(posterior[0]))
ax_posterior.barh(1, posterior[1], facecolor=posterior_colormap(posterior[1]))
# Probabilities plot details
ax_prior.set(xlim=[1, 0], yticks=[0, 1], yticklabels=['left', 'right'],
title="Prior p(s)", xticks=[])
ax_prior.yaxis.tick_right()
ax_prior.spines['left'].set_visible(False)
ax_prior.spines['bottom'].set_visible(False)
# Likelihood plot details
ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],
yticks=[0, 1], yticklabels=['left', 'right'],
ylabel='state (s)', xlabel='measurement (m)',
title='Likelihood p(m | s)')
ax_likelihood.xaxis.set_ticks_position('bottom')
ax_likelihood.spines['left'].set_visible(False)
ax_likelihood.spines['bottom'].set_visible(False)
# Posterior plot details
ax_posterior.set(xlim=[0, 1], xticks=[], yticks=[0, 1],
yticklabels=['left', 'right'],
title="Posterior p(s | m)")
ax_posterior.spines['left'].set_visible(False)
ax_posterior.spines['bottom'].set_visible(False)
# show values
ind = np.arange(2)
x,y = np.meshgrid(ind, ind)
for i in ind:
v = posterior[i]
c = f"{v:.2f}"
ax_posterior.text(v+0.2, i, c, va='center', ha='center', color='black')
for i,j in zip(x.flatten(), y.flatten()):
c = f"{likelihood[i, j]:.2f}"
ax_likelihood.text(j, i, c, va='center', ha='center', color='black')
for i in ind:
v = prior[i]
c = f"{v:.2f}"
ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')
plt.show()
return fig
def plot_utility(ps):
prior = np.asarray([ps, 1 - ps])
utility = np.array([[2, -3], [-2, 1]])
expected = prior @ utility
# definitions for the axes
left, width = 0.05, 0.16
bottom, height = 0.05, 0.9
padding = 0.02
small_width = 0.1
left_space = left + small_width + padding
added_space = padding + width
fig = plt.figure(figsize=(17, 3))
rect_prior = [left, bottom, small_width, height]
rect_utility = [left + added_space , bottom , width, height]
rect_expected = [left + 2* added_space, bottom , width, height]
ax_prior = fig.add_axes(rect_prior)
ax_utility = fig.add_axes(rect_utility, sharey=ax_prior)
ax_expected = fig.add_axes(rect_expected)
rect_colormap = plt.cm.Blues
# Data of plots
ax_prior.barh(0, prior[0], facecolor=rect_colormap(prior[0]))
ax_prior.barh(1, prior[1], facecolor=rect_colormap(prior[1]))
ax_utility.matshow(utility, cmap='cool')
norm = colors.Normalize(vmin=-3, vmax=3)
ax_expected.bar(0, expected[0], facecolor=rect_colormap(norm(expected[0])))
ax_expected.bar(1, expected[1], facecolor=rect_colormap(norm(expected[1])))
# Probabilities plot details
ax_prior.set(xlim=[1, 0], xticks=[], yticks=[0, 1],
yticklabels=['left', 'right'], title="Probability of state")
ax_prior.yaxis.tick_right()
ax_prior.spines['left'].set_visible(False)
ax_prior.spines['bottom'].set_visible(False)
# Utility plot details
ax_utility.set(xticks=[0, 1], xticklabels=['left', 'right'],
yticks=[0, 1], yticklabels=['left', 'right'],
ylabel='state (s)', xlabel='action (a)',
title='Utility')
ax_utility.xaxis.set_ticks_position('bottom')
ax_utility.spines['left'].set_visible(False)
ax_utility.spines['bottom'].set_visible(False)
# Expected utility plot details
ax_expected.set(title='Expected utility', ylim=[-3, 3],
xticks=[0, 1], xticklabels=['left', 'right'],
xlabel='action (a)', yticks=[])
ax_expected.xaxis.set_ticks_position('bottom')
ax_expected.spines['left'].set_visible(False)
ax_expected.spines['bottom'].set_visible(False)
# show values
ind = np.arange(2)
x,y = np.meshgrid(ind,ind)
for i,j in zip(x.flatten(), y.flatten()):
c = f"{utility[i, j]:.2f}"
ax_utility.text(j, i, c, va='center', ha='center', color='black')
for i in ind:
v = prior[i]
c = f"{v:.2f}"
ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')
for i in ind:
v = expected[i]
c = f"{v:.2f}"
ax_expected.text(i, 2.5, c, va='center', ha='center', color='black')
return fig
def plot_prior_likelihood_utility(ps, p_a_s1, p_a_s0, measurement):
assert 0.0 <= ps <= 1.0
assert 0.0 <= p_a_s1 <= 1.0
assert 0.0 <= p_a_s0 <= 1.0
prior = np.asarray([ps, 1 - ps])
likelihood = np.asarray([[p_a_s1, 1-p_a_s1],[p_a_s0, 1-p_a_s0]])
utility = np.array([[2.0, -3.0], [-2.0, 1.0]])
if measurement == "Fish":
posterior = likelihood[:, 0] * prior
else:
posterior = (likelihood[:, 1] * prior).reshape(-1)
posterior /= np.sum(posterior)
expected = posterior @ utility
# definitions for the axes
left, width = 0.05, 0.3
bottom, height = 0.05, 0.3
padding = 0.12
small_width = 0.2
left_space = left + small_width + padding
small_padding = 0.05
fig = plt.figure(figsize=(10, 9))
rect_prior = [left, bottom + height + padding, small_width, height]
rect_likelihood = [left_space , bottom + height + padding , width, height]
rect_posterior = [left_space + width + small_padding,
bottom + height + padding,
small_width, height]
rect_utility = [padding, bottom, width, height]
rect_expected = [padding + width + padding + left, bottom, width, height]
ax_likelihood = fig.add_axes(rect_likelihood)
ax_prior = fig.add_axes(rect_prior, sharey=ax_likelihood)
ax_posterior = fig.add_axes(rect_posterior, sharey=ax_likelihood)
ax_utility = fig.add_axes(rect_utility)
ax_expected = fig.add_axes(rect_expected)
prior_colormap = plt.cm.Blues
posterior_colormap = plt.cm.Greens
expected_colormap = plt.cm.Wistia
# Show posterior probs and marginals
ax_prior.barh(0, prior[0], facecolor=prior_colormap(prior[0]))
ax_prior.barh(1, prior[1], facecolor=prior_colormap(prior[1]))
ax_likelihood.matshow(likelihood, vmin=0., vmax=1., cmap='Reds')
ax_posterior.barh(0, posterior[0], facecolor=posterior_colormap(posterior[0]))
ax_posterior.barh(1, posterior[1], facecolor=posterior_colormap(posterior[1]))
ax_utility.matshow(utility, vmin=0., vmax=1., cmap='cool')
ax_expected.bar(0, expected[0], facecolor=expected_colormap(expected[0]))
ax_expected.bar(1, expected[1], facecolor=expected_colormap(expected[1]))
# Probabilities plot details
ax_prior.set(xlim=[1, 0], yticks=[0, 1], yticklabels=['left', 'right'],
title="Prior p(s)", xticks=[])
ax_prior.yaxis.tick_right()
ax_prior.spines['left'].set_visible(False)
ax_prior.spines['bottom'].set_visible(False)
# Likelihood plot details
ax_likelihood.set(xticks=[0, 1], xticklabels=['fish', 'no fish'],
yticks=[0, 1], yticklabels=['left', 'right'],
ylabel='state (s)', xlabel='measurement (m)',
title='Likelihood p(m | s)')
ax_likelihood.xaxis.set_ticks_position('bottom')
ax_likelihood.spines['left'].set_visible(False)
ax_likelihood.spines['bottom'].set_visible(False)
# Posterior plot details
ax_posterior.set(xlim=[0, 1], xticks=[], yticks=[0, 1],
yticklabels=['left', 'right'],
title="Posterior p(s | m)")
ax_posterior.spines['left'].set_visible(False)
ax_posterior.spines['bottom'].set_visible(False)
# Utility plot details
ax_utility.set(xticks=[0, 1], xticklabels=['left', 'right'],
xlabel='action (a)', yticks=[0, 1],
yticklabels=['left', 'right'],
title='Utility', ylabel='state (s)')
ax_utility.xaxis.set_ticks_position('bottom')
ax_utility.spines['left'].set_visible(False)
ax_utility.spines['bottom'].set_visible(False)
# Expected Utility plot details
ax_expected.set(ylim=[-2, 2], xticks=[0, 1],
xticklabels=['left', 'right'],
xlabel='action (a)',
title='Expected utility', yticks=[])
ax_expected.spines['left'].set_visible(False)
# show values
ind = np.arange(2)
x,y = np.meshgrid(ind,ind)
for i in ind:
v = posterior[i]
c = f"{v:.2f}"
ax_posterior.text(v+0.2, i, c, va='center', ha='center', color='black')
for i,j in zip(x.flatten(), y.flatten()):
c = f"{likelihood[i,j]:.2f}"
ax_likelihood.text(j, i, c, va='center', ha='center', color='black')
for i,j in zip(x.flatten(), y.flatten()):
c = f"{utility[i, j]:.2f}"
ax_utility.text(j,i, c, va='center', ha='center', color='black')
for i in ind:
v = prior[i]
c = f"{v:.2f}"
ax_prior.text(v+0.2, i, c, va='center', ha='center', color='black')
for i in ind:
v = expected[i]
c = f"{v:.2f}"
ax_expected.text(i, v, c, va='center', ha='center', color='black')
plt.show()
return fig# @title Helper Functions
def compute_marginal(px, py, cor):
""" Calculate 2x2 joint probabilities given marginals p(x=1), p(y=1) and correlation
Args:
px (scalar): marginal probability of x
py (scalar): marginal probability of y
cor (scalar): correlation value
Returns:
ndarray of size (2, 2): joint probability array of x and y
"""
p11 = px*py + cor*np.sqrt(px*py*(1-px)*(1-py))
p01 = px - p11
p10 = py - p11
p00 = 1.0 - p11 - p01 - p10
return np.asarray([[p00, p01], [p10, p11]])
def compute_cor_range(px,py):
""" Calculate the allowed range of correlation values given marginals p(x=1)
and p(y=1)
Args:
px (scalar): marginal probability of x
py (scalar): marginal probability of y
Returns:
scalar, scalar: minimum and maximum possible values of correlation
"""
def p11(corr):
return px*py + corr*np.sqrt(px*py*(1-px)*(1-py))
def p01(corr):
return px - p11(corr)
def p10(corr):
return py - p11(corr)
def p00(corr):
return 1.0 - p11(corr) - p01(corr) - p10(corr)
Cmax = min(fsolve(p01, 0.0), fsolve(p10, 0.0))
Cmin = max(fsolve(p11, 0.0), fsolve(p00, 0.0))
return Cmin, Cmaxセクション0:イントロダクション
# @title Video 1: Introduction to Bayesian Statistics and Decisions
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'Hcx2_JTpf2M'), ('Bilibili', 'BV1Ch41167jN')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Introduction_to_Bayesian_Statistics_and_Decisions_Video")セクション1:釣りに行こう
# @title Video 2: Gone Fishin'
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'kAdBjWOI_yE'), ('Bilibili', 'BV1TP4y147pJ')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Gone_Fishin_Video")このビデオでは、このチュートリアルで扱う釣りの例題について説明します。
ビデオのテキスト要約はこちらをクリック
これから探求する二値の隠れ状態問題を紹介しました。どちらの側で釣りをするか、つまり隠れた状態を決める必要があります。魚は群れをなして泳ぐことが知られています。異なる日には魚の群れは左側か右側のどちらかにいますが、今日どちらにいるかはわかりません。魚の位置に関する知識を、隠れた状態変数の確率分布として定義します。確率的な知識、すなわち隠れ状態に対する信念を用いて、今日どちらで釣りをするかの決定を、得られる利益や損失の観点から検討します。
利益と損失は、左か右かの釣りという行動を選択した際の効用によって定義されます。効用の詳細については説明されています。
次の2つのセクションでは、魚がどこにいるかの確率と、釣りをする場所を選ぶことで得られる利益や損失について考えます(ベイズ的アプローチは最後の数セクションに残します)。
自分自身を実験を行う科学者として考えるか、意思決定を行う脳として考えるかは自由です。ベイズ的アプローチは同じです!
セクション2:どこで釣るかの決定
チュートリアル開始からここまでの推定時間:10分
# @title Video 3: Utility
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', '8-5RM0k3IKE'), ('Bilibili', 'BV1uL411H7ZE')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Utility_Video")このビデオでは効用と期待効用について説明します。
ビデオのテキスト要約はこちらをクリック
どこで釣るかを決める必要があります。一見すると、魚がいる確率が高い側で釣ればよいように思えます!しかし、意思決定や行動は常にもう少し複雑です。潜水艦や日焼けの問題のように、釣りをする決定は魚の群れがいる確率だけでなく、他の要因にも影響されることがあります。あなたの行動の結果は、真の(しかし隠れた)世界の状態とあなたが選んだ行動に基づきます!この例では、魚があまりいない側で釣ると、午後は魚が釣れず日焼けしてしまう可能性が高いです。潜水艦は右側で釣るリスクが左側よりも大きいことを表しています。どちらかの側で釣る行動を取った場合に何が期待できるかを知るには、期待効用を計算する必要があります。
魚の群れが今日桟橋の左側にいる(事前)確率 はわかっています。したがって、群れが右側にいる確率 も、これら2つの確率の和が1になるためわかります。
利益と損失は効用関数 を用いて数値化します。これは、世界の状態 () とあなたの取る行動 () に対して、どれだけの価値を得るか(負の場合は損失)を表します。この例の効用は以下の通りです:
| 効用: U(s,a) | a = 左側 | a = 右側 |
|---|---|---|
| s = 左側 | +2 | -3 |
| s = 右側 | -2 | +1 |
利益や損失を考慮して行動を選ぶには、これらの効用にその状態が起こる確率を掛けて期待効用を計算します。これにより、事象の確率を考慮して行動を選べます:状態の確率が非常に低ければ、その行動と状態の組み合わせの結果が損失でも気にしません。これを数式で表すと:
つまり、行動 a の期待効用は、可能な状態すべてについて、その行動と状態の効用に状態の確率を掛けたものの和です。
インタラクティブデモ2:意思決定の探求
以下のインタラクティブデモを使って、これらがどのように機能するかを感覚的に理解しましょう。スライダーで魚の群れが左側にいる確率 を変更できます。中央に効用関数(行列)が表示され、右側に各行動の期待効用が示されます。
まず、各行動の期待効用が確率と効用値からどのように計算されているかを理解してください。初期状態では、魚が左側にいる確率は0.9、右側は0.1です。左側で釣る行動の期待効用は、 となります。要するに、行動 の期待効用は、効用行列の該当列(行動 に対応)を状態の確率で重み付けした加重和です。
以下のシナリオについて、まず考え、議論してください。その後デモを使って試し、その行動が正しかったか(期待値が最も高いか)を確認しましょう。
- 初めて桟橋に来て魚の位置がわからない場合、魚の群れが左側にいる確率を0.5(右側も0.5)と仮定します。この効用値に基づいてどちらの側で釣りますか?
- 魚の群れが左側にいる確率が非常に低い(0.1)、右側が高い(0.9)と考えた場合、どちらの側で釣りますか?
- 魚の群れが左側にいる確率が右側より少し低い(0.4対0.6)の場合はどうしますか?
# @markdown Execute this cell to use the widget
ps_widget = widgets.FloatSlider(0.9, description='p(s = left)',
min=0.0, max=1.0, step=0.01)
@widgets.interact(
ps = ps_widget,
)
def make_utility_plot(ps):
fig = plot_utility(ps)
plt.show(fig)
plt.close(fig)# @title Submit your feedback
content_review(f"{feedback_prefix}_Exploring_the_decision_Interactive_Demo_and_Discussion")# @title Video 4: Utility Demo Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'GHQbmsEyQjE'), ('Bilibili', 'BV1po4y1D7Fu')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Utility_demo_discussion_Video")このセクションでは、さまざまな状態と行動の組み合わせの効用と、各状態の確率に関する私たちの知識の両方が意思決定に影響を与えることを見てきました。重要なのは、各状態の確率に関する私たちの知識ができるだけ正確であることを望んでいるということです!
では、これらの確率をどうやって知るのでしょうか?例えば、同じ桟橋で何年も釣りをしてきたという事前知識があり、魚は左側にいる可能性が高いことを学んでいるかもしれません。もちろん、私たちは知識(信念)を更新する必要があります!そのためには、より多くの情報を収集したり、何らかの測定を行う必要があります!次のいくつかのセクションでは、確率の知識をどのように改善するかに焦点を当てます。
セクション3:魚がどちら側にいる可能性
チュートリアル開始からここまでの推定所要時間:25分
# @title Video 5: Likelihood
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'Yv8MDjdm1l4'), ('Bilibili', 'BV1EK4y1u7AV')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)ビデオのテキスト要約はこちらをクリック
まず、測定(観察や単にデータとも呼ばれます)を行うとはどういうことか、そしてそれが隠れた状態について何を教えてくれるのかを考えます。具体的には、尤度について見ていきます。これは隠れた状態()が与えられたときの測定()の確率、すなわち です。ここで隠れた状態とは、魚の群れが桟橋のどちら側にいるかを指します。
誰かが釣りをしている様子を(例えば10分間)観察し、測定はその人が魚を釣るかどうかです。魚を釣ることが魚がどちら側にいるかの尤度に何を意味するかについて何か知っています。
# @title Submit your feedback
content_review(f"{feedback_prefix}_Likelihood_Video")考えてみよう!3:魚の位置を推測する
別の桟橋に釣りに行くとしましょう。ここでは、世界の状態に応じて魚が釣れる確率が異なります。この桟橋では、魚がいる側で釣りをすると70%の確率で魚が釣れます。間違った側で釣りをすると、魚が釣れる確率は20%に下がります。これらは誰かが魚を釣るという観測の尤度です!つまり、誰かが魚を釣るかどうかを見ることで測定を行っています!
あなたは釣り人が左側で釣りをしているのを見ました。
- 以下のそれぞれを計算してください(別々に計算してから比較するとやりやすいかもしれません):
- 魚の群れが左側にいるときに魚が釣れる確率、
- 魚の群れが左側にいるときに魚が釣れない確率、
- 魚の群れが右側にいるときに魚が釣れる確率、
- 魚の群れが右側にいるときに魚が釣れない確率、
-
釣り人が魚を釣った場合、魚の群れはどちら側にいると推測しますか?その理由は?
-
釣り人が魚を釣れなかった場合、魚の群れはどちら側にいると推測しますか?その理由は?
# @title Submit your feedback
content_review(f"{feedback_prefix}_Guessing_the_location_of_the_fish_Discussion")前の演習では、誰かが釣りをしている様子を観察するという測定に基づいて魚の群れの位置を推測しようとしました。これは、測定の確率を最大化する状態(魚がいると思う側)を選ぶことで行いました。言い換えれば、尤度(状態が与えられたときの測定の確率 )を最大化することで状態を推定しました。これを最尤推定(MLE)と呼び、このコースの統計の前提知識の日やモデルフィッティングの日$で既に学んでいます!
しかし、もしあなたが何年もこの桟橋に通っていて、魚はほとんどいつも左側にいることを知っていたらどうでしょう?これは推定の仕方に影響を与えるはずです。新しい単一の測定に頼るよりも、事前知識をより重視するでしょう。これがベイズ推論の基本的な考え方であり、このチュートリアルの後半で詳しく見ていきます!
セクション4:相関と周辺化
チュートリアル開始からここまでの推定所要時間:35分
# @title Video 6: Correlation and marginalization
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'iprFMHch2_g'), ('Bilibili', 'BV1Zq4y1p7N6')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Correlation_and_marginalization_Video")セクション4.1:相関
このセクションでは少し立ち止まって、2つの確率変数間で共有される情報量についてより一般的に考えます。ある変数を観測(測定)したときに、もう一方の変数について何か知っている場合、どれだけ情報が得られるかを知りたいのです。魚のサイズと色、あるいは事前情報と尤度のように、2つの属性について考えても基本的な概念は同じであることがわかります。
考えてみよう!4.1:共変する確率分布
周辺確率と結合確率の関係は、2つの確率変数間の相関によって決まります。相関は変数がどれだけ共変するかの正規化された尺度です。これは、片方の変数の測定を観測したときにもう一方の変数について得られる情報と考えることもできます。このことをより形式的に考えるのはチュートリアル2で行います。
ここでは、魚のサイズと色の相関が、片方の属性からもう片方の属性についてどれだけ情報が得られるかにどう影響するかを考えます。相関の公式はボーナスセクション1を参照してください。
以下のウィジェットを使って、次の質問に答えてください:
- 相関がゼロ、 のとき、サイズの分布は色について何を教えてくれますか?
- を小さな値に設定します。金色の魚の確率を変えると、サイズの確率の比率はどう変わりますか? を大きく(負の値も可)設定してみてください。金色の魚の確率を変えたときにサイズの確率の変化パターンを説明できますか?
- 金色の魚と大きな魚の確率を約65%に設定します。相関が1に近づくと、銀色の大きな魚はどのくらいの頻度で見られますか?
- 相関(絶対値)が増加することは、片方の属性の魚を見たときにもう片方の属性の魚を見る可能性について何を示していますか?
# @markdown Execute this cell to enable the widget
style = {'description_width': 'initial'}
gs = GridspecLayout(2,2)
cor_widget = widgets.FloatSlider(0.0, description='ρ',
min=-1, max=1, step=0.01)
px_widget = widgets.FloatSlider(0.5, description='p(color=golden)',
min=0.01, max=0.99, step=0.01,
style=style)
py_widget = widgets.FloatSlider(0.5, description='p(size=large)',
min=0.01, max=0.99, step=0.01,
style=style)
gs[0, 0] = cor_widget
gs[0, 1] = px_widget
gs[1, 0] = py_widget
@widgets.interact(
px=px_widget,
py=py_widget,
cor=cor_widget,
)
def make_corr_plot(px, py, cor):
Cmin, Cmax = compute_cor_range(px, py) # allow correlation values
cor_widget.min, cor_widget.max = Cmin+0.01, Cmax-0.01
if cor_widget.value > Cmax:
cor_widget.value = Cmax
if cor_widget.value < Cmin:
cor_widget.value = Cmin
cor = cor_widget.value
P = compute_marginal(px,py,cor)
fig = plot_joint_probs(P)
plt.show(fig)
plt.close(fig)# @title Submit your feedback
content_review(f"{feedback_prefix}_Covarying_probability_distributions_Discussion")私たちは、2つの確率変数がどの程度独立しているかについて見てきました。相関が強いほど独立性は低く、共有情報は多くなります。また、周辺化(マージナライズ)によって測定の周辺尤度を求めたり、2つの確率変数の周辺確率分布を求めたりできることも学びました。これから、完全なベイズ推論への旅を完成させましょう!
セクション 4.2: 周辺化(マージナライズ)
関連動画のテキスト要約はこちらをクリック
ある変数の確率を求めたいが、別の変数は無視したい場合があります。その際、無関係な変数を平均化(周辺化)して取り除きます。
この考え方を2つの方法で説明します。
最初の数学演習では、2つの変数の結合確率が分かっている場合に、1つの変数の確率を求める方法を考えます。具体的には、魚の色が金色か銀色(1つ目の変数)、大きさが小さいか大きい(2つ目の変数)とします。結合確率とは、両方の属性が同時に起こる確率のことです。例えば、魚が小さくて銀色である確率 は0.4です。以下の表は結合確率をまとめたものです:
| P(X, Y) | Y = silver | Y = gold |
|---|---|---|
| X = small | 0.4 | 0.2 |
| X = large | 0.1 | 0.3 |
魚の色に関係なく、小さい魚の確率を知りたいとします。魚は銀色か金色のどちらかなので、小さくて銀色の魚の確率と小さくて金色の魚の確率を足せばよいです。これは、興味のない変数を行や列に沿って平均化(周辺化)する例です。数学的には と表せます。これにより、他の変数(ここでは色)に関係なく、ある変数の結果(ここでは大きさ)の周辺確率が得られます。
一般的には、2つ目の無関係な変数 を周辺化するには、関連する結合確率を合計します:
2つ目の数学演習では、未知の変数(隠れ状態)を取り除いて測定の周辺確率を求めます。ここでは、状態が与えられた測定の条件付き確率と各状態の確率が分かっているので、次のように周辺化します:
結合確率は、2つの変数の条件付き確率と周辺確率の積に等しいため、これら2つの周辺化の考え方(結合確率の平均化と条件付き確率による周辺化)は同値です:
数学演習 4.2.1: 周辺確率の計算
2つの変数間の情報を理解するために、まず魚の大きさと色の結合確率を考えましょう。
| P(X, Y) | Y = silver | Y = gold |
|---|---|---|
| X = small | 0.4 | 0.2 |
| X = large | 0.1 | 0.3 |
以下の問題を解いて、確率の考え方をさらに練習してください:
- 魚が銀色である確率を計算してください。
- 魚が小さい、大きい、銀色、または金色である確率を計算してください。
- 魚が小さいまたは金色である確率を計算してください。ヒント: 。
NMAでは通常数学演習はありませんが、実際に計算して理解を深めることが重要だと考えています。必要なら次のセルに計算を書き出したり、紙とペンを使ってください。まず個人で解いてから、ノートを比較し議論することをお勧めします。
"""
Joint probabilities
P( X = small, Y = silver) = 0.4
P( X = large, Y = silver) = 0.1
P( X = small, Y = gold) = 0.2
P( X = large, Y = gold) = 0.3
1. P(Y = silver) = ...
2. P(X = small or large, Y = silver or gold) = ...
3. P( X = small or Y = gold) = ...
"""# @title Submit your feedback
content_review(f"{feedback_prefix}_Computing_marginal_probabilities_Math_Exercise")数学演習 4.2.2: 周辺尤度の計算
事後分布を求めるために正規化するとき、観測した測定の周辺尤度(エビデンス)を求める必要があります。これには、先ほどのように周辺化を使って色や大きさの確率を求めます。ただし今回は、条件付き変数を取り除くために周辺化します。ここでは、右側で釣りをしている人が魚を釣る確率を考えます。
| p(m|s) | m = fish | m = no fish |
|---|---|---|
| s = left | 0.1 | 0.9 |
| s = right | 0.5 | 0.5 |
上の表は、先に学んだ尤度を示しています。
右側で釣りをしている人が魚を釣る確率 を知りたいです(事後分布を計算するために必要です)。これには事前確率 を考慮し、隠れ状態で周辺化します!
これは、興味のない変数を周辺化(条件付けを取り除く)する例でもあります。
以下の問題を解いて、確率の考え方をさらに練習してください:
- 事前確率が 、 のとき、魚が釣れる周辺尤度 を計算してください。
- 事前確率が 、 のとき、魚が釣れる周辺尤度 を計算してください。
NMAでは通常数学演習はありませんが、実際に計算して理解を深めることが重要だと考えています。必要なら次のセルに計算を書き出したり、紙とペンを使ってください。まず個人で解いてから、ノートを比較し議論することをお勧めします。
"""
Priors
P(s = left) = 0.3
P(s = right) = 0.7
Likelihoods
P(m = fish | s = left) = 0.1
P(m = fish | s = right) = 0.5
P(m = no fish | s = left) = 0.9
P(m = no fish | s = right) = 0.5
1. P(m = fish) = ...
2. P(m = fish) = ...
"""# @title Submit your feedback
content_review(f"{feedback_prefix}_Computing_marginal_likelihood_Math_Exercise")セクション 5: ベイズの定理と事後分布
チュートリアル開始からここまでの推定所要時間: 55分
# @title Video 7: Posterior Beliefs
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'cOAJQ4utwD0'), ('Bilibili', 'BV1fK4y1M7EC')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Posterior_Beliefs_Video")周辺化は、事前知識(事前分布)と測定から得られる新しい情報(尤度)を組み合わせるために使います。ここで、私たちが興味を持つ隠れ状態(魚の位置)に関する情報は、測定の確率と事前分布の関係に基づいています。
ベイズの定理を使って、隠れ状態 () の完全な事後分布を計算できます。事後分布は事前分布と尤度の積に比例することは既に見てきました。つまり、測定 () が与えられた隠れ状態 () の事後確率は、状態が与えられた測定の尤度とその状態の事前確率の積に比例します:
等号ではなく比例で表すのは、完全な確率分布にするために正規化が必要だからです:
この で正規化することで、事後分布は合計または積分が1になる完全な確率分布になります。これにより、将来の推論や意思決定にこの新しい完全な確率分布を使えます。実際、明日見るように、これを新しい事前分布として使うこともできます。最後に、この確率分布は私たちの隠れ状態に対する主観的な知識、すなわち信念として呼ばれることもあります。
行動や脳の推論をモデル化するような複雑な場合、多くは正規化項の計算が困難または非常に複雑です。解析的に事後確率を計算できる分布を選ぶか、数値近似が信頼できる場合に注意して使います。さらに良いことに、正規化を省略できる場合もあります。正規化項 は測定の確率であり、状態に依存しない定数なので無視できることが多いです。異なる状態の非正規化事後分布の値を比較することは、同じ定数で割っても関係性が変わらないため可能です。明日、異なる仮説の証拠を比較する方法としてこれを見ます。(最大尤度推定でモデルの尤度を比較する際にも使われます)
この比較的単純な例では、次の式で周辺尤度 を簡単に計算できます:
これにより正規化して完全な事後分布を扱えます。
数学演習 5: 事後確率の計算
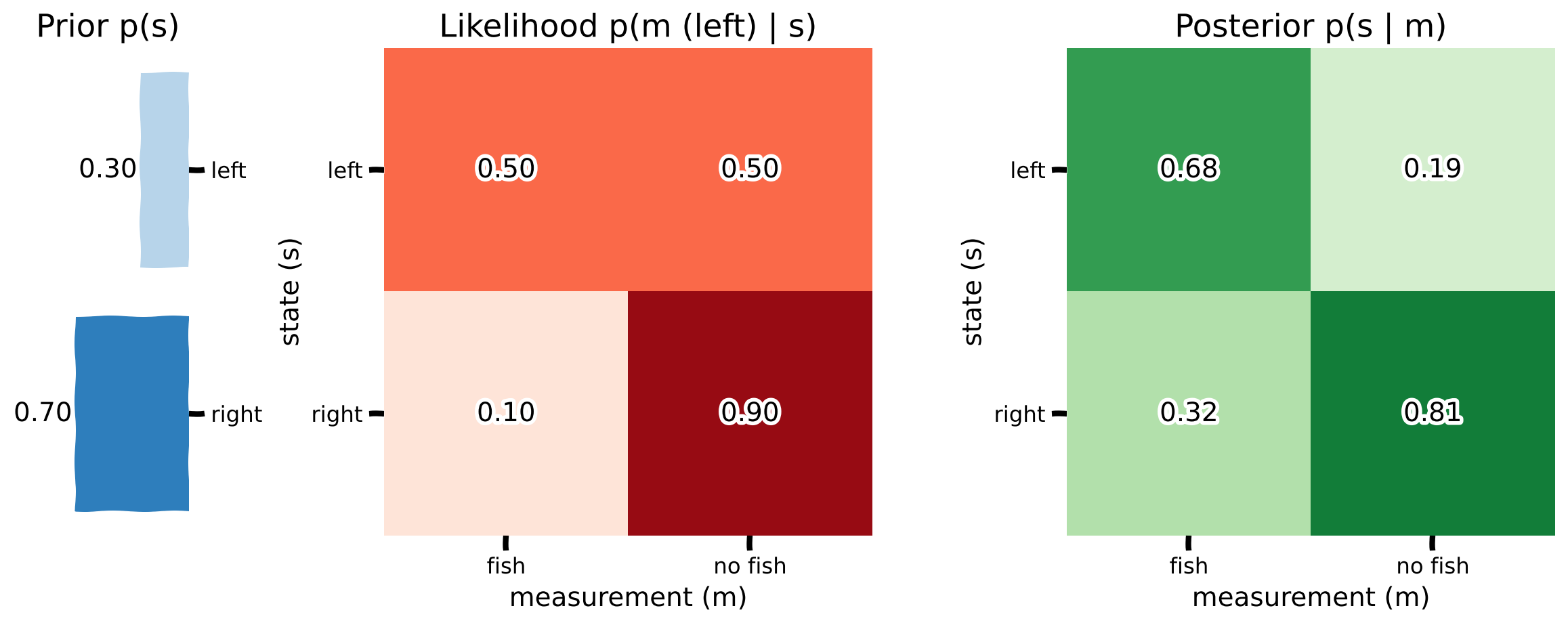
事前確率は 、 です。動画で、魚群と同じ側で釣りをすると魚が釣れる確率は50%、それ以外は10%と学びました。左側で釣りをしている人を観察します。尤度は以下の通りです:
| 尤度: p(m | s) | m = fish | m = no fish |
|---|---|---|
| s = left | 0.5 | 0.5 |
| s = right | 0.1 | 0.9 |
以下の事後確率を計算してください(紙に書いてもよいです):
- 釣り人が魚を釣った場合、魚群が左側にいる確率 (ヒント: を計算して正規化してください)
- 釣り人が魚を釣らなかった場合、魚群が右側にいる確率
NMAでは通常数学演習はありませんが、実際に計算して理解を深めることが重要だと考えています。必要なら次のセルに計算を書き出したり、紙とペンを使ってください。まず個人で解いてから、ノートを比較し議論することをお勧めします。
"""
Priors
p(s = left) = 0.3
p(s = right) = 0.7
Likelihoods
P(m = fish | s = left) = 0.5
P(m = fish | s = right) = 0.1
P(m = no fish | s = left) = 0.5
P(m = no fish | s = right) = 0.9
1. p( s = left | m = fish) = ...
2. p( s = right | m = no fish ) = ...
"""# @title Submit your feedback
content_review(f"{feedback_prefix}_Calculating_a_posterior_probability_Math_Exercise")コーディング演習 5: 事後確率の計算
上記の数学を実装して、異なる事前確率と尤度に対する事後確率を計算できるようにしましょう。
前回と同様に、事前確率は 、 です。ビデオでは、群れと同じ側で釣りをした場合に魚が釣れる確率は50%で、それ以外の場合は10%であることを学びました。左側で釣りをしている人を観察しました。尤度は以下の通りです:
| 尤度: p(m | s) | m = 魚が釣れた | m = 魚が釣れなかった |
|---|---|---|
| s = left | 0.5 | 0.5 |
| s = right | 0.1 | 0.9 |
完全な事後確率も同じ2×2の形式にしたいです。出力が数学の答えと一致していることを確認してください!
def compute_posterior(likelihood, prior):
""" Use Bayes' Rule to compute posterior from likelihood and prior
Args:
likelihood (ndarray): i x j array with likelihood probabilities where i is
number of state options, j is number of measurement options
prior (ndarray): i x 1 array with prior probability of each state
Returns:
ndarray: i x j array with posterior probabilities where i is
number of state options, j is number of measurement options
"""
#################################################
## TODO for students ##
# Fill out function and remove
raise NotImplementedError("Student exercise: implement compute_posterior")
#################################################
# Compute unnormalized posterior (likelihood times prior)
posterior = ... # first row is s = left, second row is s = right
# Compute p(m)
p_m = np.sum(posterior, axis = 0)
# Normalize posterior (divide elements by p_m)
posterior /= ...
return posterior
# Make prior
prior = np.array([0.3, 0.7]).reshape((2, 1)) # first row is s = left, second row is s = right
# Make likelihood
likelihood = np.array([[0.5, 0.5], [0.1, 0.9]]) # first row is s = left, second row is s = right
# Compute posterior
posterior = compute_posterior(likelihood, prior)
# Visualize
plot_prior_likelihood_posterior(prior, likelihood, posterior)出力例:
# @title Submit your feedback
content_review(f"{feedback_prefix}_Computing_Posteriors_Exercise")インタラクティブデモ 5: 何が事後確率に影響を与えるか?
ベイズの定理の実装が理解できたので、事前確率と尤度のパラメータを変化させて、事前確率や尤度の変化が事後確率にどのように影響するかを見てみましょう。
以下のデモでは、 のスライダーを動かして事前確率を変更できます。また、群れが左にいる場合に魚が釣れる確率と、群れが右にいる場合に魚が釣れる確率を変えて尤度も変更できます。観察している釣り人は左側で釣りをしています。
- 尤度を一定に保った場合、事前確率が事後確率に最も強く影響するのはどんな時でしょうか?つまり、魚が釣れたかどうかに関わらず、事後確率が事前確率に最も似ているのはいつでしょうか?
- 正しい側または間違った側で釣りをしたときの魚が釣れる確率が似ている場合はどうなりますか?
- 状態が左である事前確率を0.6に設定し、尤度を変えてみましょう。尤度が事後確率に最も影響を与えるのはどんな時でしょうか?
# @markdown Execute this cell to enable the widget
# style = {'description_width': 'initial'}
ps_widget = widgets.FloatSlider(0.3, description='p(s = left)',
min=0.01, max=0.99, step=0.01)
p_a_s1_widget = widgets.FloatSlider(0.5,
description='p(fish on left | state = left)',
min=0.01, max=0.99, step=0.01, style=style,
layout=Layout(width='370px'))
p_a_s0_widget = widgets.FloatSlider(0.1,
description='p(fish on left | state = right)',
min=0.01, max=0.99, step=0.01, style=style,
layout=Layout(width='370px'))
observed_widget = ToggleButtons(options=['Fish', 'No Fish'],
description='Observation (m) on the left:', disabled=False, button_style='',
layout=Layout(width='auto', display="flex"),
style={'description_width': 'initial'}
)
widget_ui = VBox([ps_widget,
HBox([p_a_s1_widget, p_a_s0_widget]),
observed_widget])
widget_out = interactive_output(plot_prior_likelihood,
{'ps': ps_widget,
'p_a_s1': p_a_s1_widget,
'p_a_s0': p_a_s0_widget,
'measurement': observed_widget})
display(widget_ui, widget_out)# @title Submit your feedback
content_review(f"{feedback_prefix}_What_affects_the_posterior_Interactive_Demo_and_Discussion")# @title Video 8: Posterior Beliefs Exercises Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'YPQgLVolvBs'), ('Bilibili', 'BV1TU4y1G7SM')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Posterior_Beliefs_Exercises_Discussion_Video")セクション 6: ベイズ的釣りの意思決定
チュートリアル開始からここまでの推定所要時間: 1時間15分
# @title Video 9: Bayesian Decisions
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'tz9zsmTHR68'), ('Bilibili', 'BV1954y1n7uH')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Bayesian_Decisions_Video")魚がいる場所に関する私たちの信念(事後分布)に基づいて、行動の期待効用をどのように考えるかを探ります。これで、ベイズ的意思決定のすべての要素が揃いました:事前情報、観測に基づく尤度、事後分布(信念)、そして効用(利益と損失)です。これにより、隠れた状態 の真の値と、信念に基づいて行動 を取った場合に期待される結果との関係を考えることができます!
以下のウィジェットを使って、これらの確率分布と効用関数の関係を考えてみましょう。
インタラクティブデモ!6: どちらがより重要か、確率か効用か?
ここまで学んだことをすべて組み合わせて、ベイズ的意思決定に関わる各要素がどのように結びつくかの直感を得ていきます。神経科学、心理学、経済学、生態学などで共通している仮定は、私たち(人間や動物)は期待効用を最大化しようとしているということです。このデモは、このチュートリアルの内容をすべて一箇所にまとめているため、多くの要素が含まれています。コントロールやプロットがどのように関連しているかを特に理解するために時間をかけてください。
- 期待効用が両方の行動で同じになる状況を見つけられますか?
- 期待効用を決定する上でより重要なのは、事前分布(prior)ですか、それとも新しい測定値(尤度)ですか?
- なぜこれは規範的モデル(ノルマティブモデル)と言えるのでしょうか?
- このモデルを人間や動物の行動を説明するために拡張する必要があるとしたら、どのような方法が考えられますか?
# @markdown Execute this cell to enable the widget
# style = {'description_width': 'initial'}
ps_widget = widgets.FloatSlider(0.3, description='p(s = left)',
min=0.01, max=0.99, step=0.01,
layout=Layout(width='300px'))
p_a_s1_widget = widgets.FloatSlider(0.5,
description='p(fish on left | state = left)',
min=0.01, max=0.99, step=0.01,
style=style, layout=Layout(width='370px'))
p_a_s0_widget = widgets.FloatSlider(0.1,
description='p(fish on left | state = right)',
min=0.01, max=0.99, step=0.01,
style=style, layout=Layout(width='370px'))
observed_widget = ToggleButtons(options=['Fish', 'No Fish'],
description='Observation (m) on the left:', disabled=False, button_style='',
layout=Layout(width='auto', display="flex"),
style={'description_width': 'initial'}
)
widget_ui = VBox([ps_widget,
HBox([p_a_s1_widget, p_a_s0_widget]),
observed_widget])
widget_out = interactive_output(plot_prior_likelihood_utility,
{'ps': ps_widget,
'p_a_s1': p_a_s1_widget,
'p_a_s0': p_a_s0_widget,
'measurement': observed_widget})
display(widget_ui, widget_out)# @title Submit your feedback
content_review(f"{feedback_prefix}_Probabilities_vs_utilities_Interactive_Demo_and_Discussion")# @title Video 10: Bayesian Decisions Demo Discussion
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'h9L0EYmUpHs'), ('Bilibili', 'BV1QU4y137BS')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Bayesian_Decisions_Demo_Discussion_Video")まとめ
チュートリアルの推定所要時間:1時間30分
このチュートリアルでは、釣りの問題を題材に、ベイズ則を用いて事前情報と新しい測定値を組み合わせて知識を更新する方法を学びました。
具体的には以下の内容を扱いました:
-
尤度(likelihood)は、ある隠れた状態が与えられたときの測定値の確率であること
-
事前分布と尤度がどのように相互作用して事後分布(測定値が与えられたときの隠れた状態の確率)を作るかは、それらの共分散に依存すること
-
効用(utility)は各行動と状態の組み合わせから得られる利益であり、ある行動の期待効用は、その状態が起こる確率で重み付けされたすべての状態の効用の和であること。最終的に期待効用が最も高い行動を選択できること
ボーナス
ボーナスセクション 1: 相関の公式
相関の計算方法を理解するために、共分散と相関の定義を復習しましょう。
共分散:
\begin{align}
&= [ (X - [X])(Y - [Y]) ] \
&= [ XY - X[Y] - [X]Y + [X][Y] ] \
&= [XY] - [X][Y] - [X][Y] + [X][Y]\
&= [XY] - [X][Y].
\end{align}
相関: