![]()

チュートリアル 1: ニューラル応答のデコード
第1週 第5日目: ディープラーニング
Neuromatch Academyによる
コンテンツ作成者: Jorge A. Menendez, Carsen Stringer
コンテンツレビュアー: Roozbeh Farhoodi, Madineh Sarvestani, Kshitij Dwivedi, Spiros Chavlis, Ella Batty, Michael Waskom
制作編集者: Spiros Chavlis
チュートリアルの目的
推定所要時間: 1時間20分
このチュートリアルでは、ディープラーニングを用いて感覚ニューロンの応答から刺激情報をデコードします。具体的には、この研究で記録された、マウスの一次視覚野における約20,000個のニューロンの傾き格子刺激に対する活動を見ていきます。課題は、ニューロン集団全体の応答から提示された刺激の傾きをデコードすることです。これにはさまざまな方法がありますが、ここではディープラーニングを使用します。ディープラーニングがこの問題に特に適している理由は以下の通りです:
- データは非常に高次元です:刺激に対するニューロンの応答は約20,000次元のベクトルです。多くの機械学習手法はこのような高次元ではうまく機能しませんが、十分なデータがあれば(今回のデータは十分です!)ディープラーニングはこの領域で優れた性能を発揮します。
- 下記で確認できるように、異なるニューロンは刺激に対してかなり異なる応答を示します。この複雑な応答パターンをデコードするには非線形手法が必要であり、ディープネットワークの非線形活性化関数を使うことで簡単に実現できます。
- ディープラーニングのアーキテクチャは非常に柔軟であり、デコードモデルの構造を簡単に調整して最適化できます。ここでは単一のアーキテクチャに焦点を当てますが、コードのわずかな変更で簡単に修正可能です。
より具体的には、以下を学びます:
- PyTorchを使ってディープフィードフォワードネットワークを構築する方法
- PyTorchの組み込み損失関数を用いてネットワークの出力を評価する方法
- 自動微分を用いて損失の各パラメータに対する勾配を計算する方法
- 勾配降下法を実装してネットワークのパラメータを最適化する方法
# @title Tutorial slides
# @markdown These are the slides for all videos in this tutorial.
from IPython.display import IFrame
link_id = "vb7c4"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)セットアップ
# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W1D5_T1"# Imports
import os
import numpy as np
import torch
from torch import nn
from torch import optim
import matplotlib as mpl
from matplotlib import pyplot as plt# @title Figure Settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")# @title Plotting Functions
def plot_data_matrix(X, ax, show=False):
"""Visualize data matrix of neural responses using a heatmap
Args:
X (torch.Tensor or np.ndarray): matrix of neural responses to visualize
with a heatmap
ax (matplotlib axes): where to plot
show (boolean): enable plt.show()
"""
cax = ax.imshow(X, cmap=mpl.cm.pink, vmin=np.percentile(X, 1),
vmax=np.percentile(X, 99))
cbar = plt.colorbar(cax, ax=ax, label='normalized neural response')
ax.set_aspect('auto')
ax.set_xticks([])
ax.set_yticks([])
if show:
plt.show()
def plot_train_loss(train_loss):
plt.plot(train_loss)
plt.xlim([0, None])
plt.ylim([0, None])
plt.xlabel('iterations of gradient descent')
plt.ylabel('mean squared error')
plt.show()# @title Helper Functions
def load_data(data_name, bin_width=1):
"""Load mouse V1 data from Stringer et al. (2019)
Data from study reported in this preprint:
https://www.biorxiv.org/content/10.1101/679324v2.abstract
These data comprise time-averaged responses of ~20,000 neurons
to ~4,000 stimulus gratings of different orientations, recorded
through Calcium imaging. The responses have been normalized by
spontaneous levels of activity and then z-scored over stimuli, so
expect negative numbers. They have also been binned and averaged
to each degree of orientation.
This function returns the relevant data (neural responses and
stimulus orientations) in a torch.Tensor of data type torch.float32
in order to match the default data type for nn.Parameters in
Google Colab.
This function will actually average responses to stimuli with orientations
falling within bins specified by the bin_width argument. This helps
produce individual neural "responses" with smoother and more
interpretable tuning curves.
Args:
bin_width (float): size of stimulus bins over which to average neural
responses
Returns:
resp (torch.Tensor): n_stimuli x n_neurons matrix of neural responses,
each row contains the responses of each neuron to a given stimulus.
As mentioned above, neural "response" is actually an average over
responses to stimuli with similar angles falling within specified bins.
stimuli: (torch.Tensor): n_stimuli x 1 column vector with orientation
of each stimulus, in degrees. This is actually the mean orientation
of all stimuli in each bin.
"""
with np.load(data_name) as dobj:
data = dict(**dobj)
resp = data['resp']
stimuli = data['stimuli']
if bin_width > 1:
# Bin neural responses and stimuli
bins = np.digitize(stimuli, np.arange(0, 360 + bin_width, bin_width))
stimuli_binned = np.array([stimuli[bins == i].mean() for i in np.unique(bins)])
resp_binned = np.array([resp[bins == i, :].mean(0) for i in np.unique(bins)])
else:
resp_binned = resp
stimuli_binned = stimuli
# Return as torch.Tensor
resp_tensor = torch.tensor(resp_binned, dtype=torch.float32)
stimuli_tensor = torch.tensor(stimuli_binned, dtype=torch.float32).unsqueeze(1) # add singleton dimension to make a column vector
return resp_tensor, stimuli_tensor
def get_data(n_stim, train_data, train_labels):
""" Return n_stim randomly drawn stimuli/resp pairs
Args:
n_stim (scalar): number of stimuli to draw
resp (torch.Tensor):
train_data (torch.Tensor): n_train x n_neurons tensor with neural
responses to train on
train_labels (torch.Tensor): n_train x 1 tensor with orientations of the
stimuli corresponding to each row of train_data, in radians
Returns:
(torch.Tensor, torch.Tensor): n_stim x n_neurons tensor of neural responses and n_stim x 1 of orientations respectively
"""
n_stimuli = train_labels.shape[0]
istim = np.random.choice(n_stimuli, n_stim)
r = train_data[istim] # neural responses to this stimulus
ori = train_labels[istim] # true stimulus orientation
return r, ori# @title Data retrieval and loading
import hashlib
import requests
fname = "W3D4_stringer_oribinned1.npz"
url = "https://osf.io/683xc/download"
expected_md5 = "436599dfd8ebe6019f066c38aed20580"
if not os.path.isfile(fname):
try:
r = requests.get(url)
except requests.ConnectionError:
print("!!! Failed to download data !!!")
else:
if r.status_code != requests.codes.ok:
print("!!! Failed to download data !!!")
elif hashlib.md5(r.content).hexdigest() != expected_md5:
print("!!! Data download appears corrupted !!!")
else:
with open(fname, "wb") as fid:
fid.write(r.content)セクション0: デコーディングタスク
以下のビデオでは、本チュートリアルで使用するデコーディングタスク、すなわち1つの隠れ層を持つ線形ネットワークと、それをPyTorchで構築する方法について説明します。
Generalized Linear Model Day$では、一般化線形モデルがデコーディングおよびエンコーディングモデルとして使われました。神経活動から変数をデコードするモデルは、その変数に関して脳の領域がどれだけの情報を持っているかを示すことができます。エンコーディングモデルは、視覚刺激のような入力変数から神経活動へのモデルです。エンコーディングモデルは脳が入力変数に対して行う変換を近似することを目的としており、したがって脳が情報をどのように表現しているかを理解するのに役立ちます。今日は、深層ニューラルネットワークを使ってこれらのモデルを構築します。なぜなら、深層ニューラルネットワークは幅広い非線形関数を近似でき、かつ簡単にフィットさせることができるからです。
# @title Video 1: Decoding from neural data using feed-forward networks in pytorch
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'SlrbMvvBOzM'), ('Bilibili', 'BV1Xa4y1a7Jz')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Decoding_from_neural_data_Video")セクション1: データの読み込み、分割、可視化
ビデオの該当部分のテキスト要約はこちらをクリック
私たちは、マウスが目の前のスクリーンに表示される傾きのあるグレーティング刺激を見ている間の神経活動を調べます。神経活動は二光子カルシウムイメージングという技術を使って記録します。これにより、何千ものニューロンを同時に記録できます。ニューロンは発火すると光ります。次に、このイメージングデータを刺激ごとの神経応答の行列に変換します。このチュートリアルの目的のために、神経応答をビニングし、各ニューロンのチューニングカーブを計算します。ビン幅は1度に設定しました。1つのビン内の全ニューロンの応答を使って、どの刺激が提示されたかを予測しようとします。つまり、24000個のニューロンの応答を使って、360通りの異なる刺激条件(各度数の傾きに対応)を予測することになり、大規模データの領域に入っています!
次のセルでは、データを読み込み、神経応答の行列をプロットするコードを提供しています。
隣のセルでは、ランダムに選んだ3つのニューロンのチューニングカーブをプロットしています。これらのチューニングカーブは、各ニューロンの1内の傾き刺激に対する平均応答であり、全体で360あるため360の応答があります。
実際の記録では何千もの刺激が提示されましたが、実験で変化させた変数(ここでは刺激の傾き)に対する平均応答を可視化したいため、チューニングカーブを作成することが多いです。
# @markdown Execute this cell to load and visualize data
# Load data
resp_all, stimuli_all = load_data(fname) # argument to this function specifies bin width
n_stimuli, n_neurons = resp_all.shape
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(2 * 6, 5))
# Visualize data matrix
plot_data_matrix(resp_all[:, :100].T, ax1) # plot responses of first 100 neurons
ax1.set_xlabel('stimulus')
ax1.set_ylabel('neuron')
# Plot tuning curves of three random neurons
ineurons = np.random.choice(n_neurons, 3, replace=False) # pick three random neurons
ax2.plot(stimuli_all, resp_all[:, ineurons])
ax2.set_xlabel('stimulus orientation ($^o$)')
ax2.set_ylabel('neural response')
ax2.set_xticks(np.linspace(0, 360, 5))
fig.suptitle(f'{n_neurons} neurons in response to {n_stimuli} stimuli')
fig.tight_layout()
plt.show()データを訓練セットとテストセットに分割します。具体的には、訓練セットとして傾き(stimuli_train)と対応する応答(resp_train)を用意し、テストセットとして保持した傾き(stimuli_test)と対応する応答(resp_test)を用意します。
# @markdown Execute this cell to split into training and test sets
# Set random seeds for reproducibility
np.random.seed(4)
torch.manual_seed(4)
# Split data into training set and testing set
n_train = int(0.6 * n_stimuli) # use 60% of all data for training set
ishuffle = torch.randperm(n_stimuli)
itrain = ishuffle[:n_train] # indices of data samples to include in training set
itest = ishuffle[n_train:] # indices of data samples to include in testing set
stimuli_test = stimuli_all[itest]
resp_test = resp_all[itest]
stimuli_train = stimuli_all[itrain]
resp_train = resp_all[itrain]セクション 2: pytorch による深層フィードフォワードネットワーク
動画の関連部分のテキスト要約はこちらをクリック
隠れ層を持たない線形ネットワークを構築できます。ここで刺激の予測値 は重み と神経応答 の積に、バイアス項と呼ばれる を加えたものです。このような線形モデルをフィットさせるときは、予測された刺激 と真の刺激 との二乗誤差を最小化します。これが「損失関数」です。
\begin{align}
L &= (y - \
&= ((\mathbf{W}^{out} \mathbf{r} + \mathbf{b}) - \tilde{y})^2
\end{align}
この損失関数を最小化する解は線形モデルでは閉形式で求められます。もし覚えていれば、最初の週にこの線形回帰問題の解き方を学びました。このデータに単純な線形モデルを使うと、刺激を2〜3度の誤差で予測できます。では、深層ネットワークで神経活動をより良く予測できるか試してみましょう。
この線形モデルに 個のユニットを持つ隠れ層を追加すると、出力 は次のようになります:
\begin{align}
&= && [: M , , , : M ] , , \
y &= && [: 1 , , , : 1 ] , ,
\end{align}
ここで、 個の隠れユニットを持つこの1層の隠れ層を持つ線形ネットワークは、入力数 より小さい の場合、縮小ランク回帰を行っているのと同等であり、これは回帰モデルの正則化に有用な手法です。
この隠れ層を追加することで、モデルの深さは になります。ユニット数 はネットワークの幅と呼ばれます。ネットワークの深さと幅を増やすことで、モデルの表現力、つまり複雑な非線形関数をどれだけうまくフィットできるかが向上します。現在の最先端モデルは100層近くあるものもあります!しかし今回は、深さ のモデルから始めて、刺激の予測が改善できるか見てみましょう。より深い議論や、深さや幅の選択が意味すること、いつ深い/浅い、広い/狭いアーキテクチャを使うべきかについてはボーナスセクション1を参照してください。
次元のベクトル はネットワークの隠れ層の活性化を表します。この図の青い部分はネットワークのパラメータを示しており、後で勾配降下法で最適化します。これにはすべての重みとバイアス が含まれます。重みは各層の入力に掛けられるサイズ(出力数 × 入力数)の行列で、線形回帰の回帰係数のようなものです。バイアスはサイズ(出力数 × 1)のベクトルで、線形回帰の切片項のようなものです(多変量線形回帰の詳細はW1D3を参照)。

これから、神経応答のベクトルを入力として受け取り、デコードされた刺激の向きを表す単一の数値を出力するシンプルな深層ニューラルネットワークを構築します。
番目の刺激に対する神経応答のベクトルを とします。このネットワークは以下の式で表されます:
\begin{align}
&= && [: M , , , : M ] , , \
&= && [: 1 , , , : 1 ] , ,
\end{align}
ここで はネットワークのスカラー出力であり、 番目の刺激のデコードされた向きを表します。
セクション 2.1: PyTorch 入門
チュートリアル開始からここまでの推定所要時間: 16分
ここでは、Pythonでこの形式の深層ネットワークを構築、実行、訓練するためにPyTorchパッケージを使用します。PyTorchはtorch.Tensorというデータ型を使います。これは実質的にnumpy配列と同じですが、自動微分(後述)に必要な重要な属性やメソッドを備えています。また、GPU上での保存や計算を簡単に行うためのインフラも備わっており、ここでは触れませんが実際には非常に便利です。
動画の関連部分のテキストまとめはこちらをクリック
まず、PyTorchライブラリのtorchとそのニューラルネットワークモジュールnnをインポートします。次に、DeepNetという深層ネットワークのクラスを作成します。クラスにはメソッドと呼ばれる関数があります。Pythonのクラスは__init__というメソッドで初期化されます。この場合、__init__メソッドはクラス自身を表すself以外にn_inputsとn_hiddenという2つの入力を受け取るよう宣言されています。ここでn_inputsは予測に使うニューロンの数、n_hiddenは隠れユニットの数です。まず、super関数を呼び出してnn.Moduleの初期化関数を実行します。次に、隠れ層in_layerをクラスの属性として追加します。これはnn.Linearという線形層で、サイズはn_inputs×n_hiddenです。さらに、2番目の線形層out_layerをn_hidden×1のサイズで追加します。これは刺激の向きという1つの出力を予測するためです。PyTorchはすべての重みとバイアスをランダムに初期化します。
隠れユニットの数n_hiddenは、ネットワークの構築方法を決める際に自由に変えられるパラメータです。このアーキテクチャの選択がネットワークの計算能力にどのように影響するかについては、ボーナスセクション1を参照してください。
次に、forwardという別のメソッドをクラスに追加します。これはクラスを関数のように呼び出したときに実行されるメソッドです。入力として神経応答rを受け取り、rを線形層in_layerとout_layerに通して予測結果yを返します。200個の隠れユニットでこのクラスのインスタンスnetをnet = DeepNet(n_neurons, 200)のように作成しましょう。これで神経応答をネットワークに通して刺激を予測できます(net(r))。このように「net」を実行するとforwardメソッドが呼ばれます。
次のセルには、上記および動画で定義した深層ネットワークを、深層ニューラルネットワークモデルのベースクラスであるnn.Moduleを使って構築するコードが含まれています(ドキュメントはこちら)。
class DeepNet(nn.Module):
"""Deep Network with one hidden layer
Args:
n_inputs (int): number of input units
n_hidden (int): number of units in hidden layer
Attributes:
in_layer (nn.Linear): weights and biases of input layer
out_layer (nn.Linear): weights and biases of output layer
"""
def __init__(self, n_inputs, n_hidden):
super().__init__() # needed to invoke the properties of the parent class nn.Module
self.in_layer = nn.Linear(n_inputs, n_hidden) # neural activity --> hidden units
self.out_layer = nn.Linear(n_hidden, 1) # hidden units --> output
def forward(self, r):
"""Decode stimulus orientation from neural responses
Args:
r (torch.Tensor): vector of neural responses to decode, must be of
length n_inputs. Can also be a tensor of shape n_stimuli x n_inputs,
containing n_stimuli vectors of neural responses
Returns:
torch.Tensor: network outputs for each input provided in r. If
r is a vector, then y is a 1D tensor of length 1. If r is a 2D
tensor then y is a 2D tensor of shape n_stimuli x 1.
"""
h = self.in_layer(r) # hidden representation
y = self.out_layer(h)
return yセクション 2.2: 活性化関数
チュートリアル開始からここまでの推定所要時間: 25分
# @title Video 2: Nonlinear activation functions
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'JAdukDCQALA'), ('Bilibili', 'BV1m5411h7V5')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Nonlinear_activation_functions_Video")このビデオでは、線形ネットワークに非線形活性化関数、具体的には整流線形ユニット(ReLU)を追加する方法を解説します。
ビデオのテキスト要約はこちらをクリック
上で構築した深層ネットワークは、各層がすべて線形演算で構成されていることに注意してください。各層は前の層のすべての要素の重み付き和にすぎません。実は、このような線形の隠れ層はあまり有用ではありません。なぜなら、線形変換の連続は本質的に単一の線形変換と同じだからです。上記の式から、最初の式を2番目の式に代入すると次のようになります。
言い換えれば、出力は依然として入力の要素の重み付き和にすぎず、隠れ層はこれを変化させていません。
計算可能な入出力変換の範囲を単なる重み付き和以上に拡張するために、隠れユニットに非線形活性化関数を組み込みます。これは単に隠れ層の活性化の式を次のように修正することで行います。
ここで、 は活性化関数と呼ばれます。非線形活性化関数を使うことで、隠れ層は入力に対して非線形変換を行い、ネットワークははるかに強力(または表現力豊か、ボーナスセクション1参照)になります。実際、深層ネットワークは常に非線形活性化関数を使用します。
最も一般的に使われる非線形関数は整流線形ユニット(ReLU)で、これは max(0, x) 関数です。ニューラルネットワークの開発初期には、シグモイド関数やtanh関数など様々な非線形関数が試されましたが、最終的にReLU活性化関数が最も効果的であることがわかりました。これは、入力が正の値であれば勾配がネットワークを通じて逆伝播できるためです。xが0より大きいすべての値で勾配は1です。飽和型の非線形関数を使うと、飽和領域で勾配が非常に小さくなり、ユニットの実効的な計算領域が狭まってしまいます。
コーディング演習 2.2: 非線形活性化関数
上記のディープネットワークモデルを修正して、非線形活性化関数 を追加した新しいクラス DeepNetReLU を作成してください:
ここでは線形整流関数を使用します:
これは PyTorch の torch.relu() を使って実装できます。この活性化関数を持つ隠れ層は一般に「Rectified Linear Units」、略して ReLU と呼ばれます。
このネットワークを隠れユニット数10で初期化し、例の刺激に対して実行してください。
ヒント: 上記の DeepNet() クラスの forward() メソッドを修正して torch.relu() を含めるだけで十分です。
次にこのネットワークを初期化して実行します。最初の刺激に対するニューロン応答ベクトル r から刺激の向き(真の刺激は ori で与えられます)をデコードします。初期化されたネットワーククラスは入力に対して関数のように呼び出すと(例:net(r))、その .forward() メソッドが呼ばれます。これは nn.Module クラスの特別な性質です。
この時点でのデコードされた向きはランダムな重みで初期化されているため意味をなさないことに注意してください。以下でこれらの重みを最適化して良い刺激デコードを学習する方法を説明します。
class DeepNetReLU(nn.Module):
""" network with a single hidden layer h with a RELU """
def __init__(self, n_inputs, n_hidden):
super().__init__() # needed to invoke the properties of the parent class nn.Module
self.in_layer = nn.Linear(n_inputs, n_hidden) # neural activity --> hidden units
self.out_layer = nn.Linear(n_hidden, 1) # hidden units --> output
def forward(self, r):
############################################################################
## TO DO for students: write code for computing network output using a
## rectified linear activation function for the hidden units
# Fill out function and remove
raise NotImplementedError("Student exercise: complete DeepNetReLU forward")
############################################################################
h = ... # h is size (n_inputs, n_hidden)
y = ... # y is size (n_inputs, 1)
return y
# Set random seeds for reproducibility
np.random.seed(1)
torch.manual_seed(1)
# Initialize a deep network with M=200 hidden units
net = DeepNetReLU(n_neurons, 200)
# Get neural responses (r) to and orientation (ori) to one stimulus in dataset
r, ori = get_data(1, resp_train, stimuli_train) # using helper function get_data
# Decode orientation from these neural responses using initialized network
out = net(r) # compute output from network, equivalent to net.forward(r)
print(f'decoded orientation: {out.item():.2f} degrees')
print(f'true orientation: {ori.item():.2f} degrees')デコードされた向きは 0.17 で、真の向きは 139.00 です。以下のように表示されるはずです:
decoded orientation: 0.17 degrees
true orientation: 139.00 degrees
# @title Submit your feedback
content_review(f"{feedback_prefix}_Nonlinear_activations_Exercise")セクション 3: 損失関数と勾配降下法
# @title Video 3: Loss functions & gradient descent
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'aEtKpzEuviw'), ('Bilibili', 'BV19k4y1271n')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Loss_functions_and_gradient_descent_Video")このビデオでは、損失関数、勾配降下法、およびこれらをPyTorchで実装する方法について説明します。
セクション 3.1: 損失関数
チュートリアル開始からここまでの推定時間: 40分
ネットワークの重みは現在ランダムに選ばれているため、ネットワークの出力は意味を成しません:デコードされた刺激の向きは真の刺激の向きから全く離れています。まもなく、これらの重みを変更してネットワークがより良くデコードできるようにするコードを書きます。
しかし、そのためにはまず「より良い」とは何かを定義する必要があります。これを定義する簡単な方法の一つは二乗誤差を使うことです。
ここで、 はネットワークの出力、 は真の刺激の向きです。デコードされた刺激の向きが真の刺激の向きから遠いほど、 は大きくなります。したがって、 は損失関数と呼ばれ、刺激の向きをデコードするネットワークの「悪さ」を定量化します。
ビデオの関連部分のテキスト要約はこちらをクリック
まず、神経応答をネットワーク net に通して出力 out を得ます。次に損失関数を宣言します。ここでは組み込みの nn.MSELoss 関数を使用します:loss_fn = nn.MSELoss()。この損失関数は2つの入力、ネットワーク出力 out と真の刺激の向き ori を取り、平均二乗誤差を計算します:loss = loss_fn(out, ori)。具体的には、バッチ内のネットワーク出力 と対応するターゲット出力 を引数に取り、平均二乗誤差 (MSE) を計算します。
ここで、 はバッチ内の異なる刺激の数で、バッチサイズと呼ばれます。
MSEの計算
のReLUユニットを持つ深層ネットワークで、20個のランダム刺激に対する神経応答からデコードされた向きの平均二乗誤差を評価します。
# Set random seeds for reproducibility
np.random.seed(1)
torch.manual_seed(1)
# Initialize a deep network with M=10 hidden units
net = DeepNetReLU(n_neurons, 10)
# Get neural responses to first 20 stimuli in the data set
r, ori = get_data(20, resp_train, stimuli_train)
# Decode orientation from these neural responses
out = net(r)
# Initialize PyTorch mean squared error loss function (Hint: look at nn.MSELoss)
loss_fn = nn.MSELoss()
# Evaluate mean squared error
loss = loss_fn(out, ori)
print(f'mean squared error: {loss:.2f}')平均二乗誤差は42949.14になるはずです。
セクション 3.2: 勾配降下法による最適化
チュートリアル開始からここまでの推定時間: 50分
ビデオの関連部分のテキスト要約はこちらをクリック
次に、この損失関数を勾配降下法で最小化します。勾配降下法では、損失関数の各パラメータ(すべての と )に関する勾配を計算します。次に、パラメータを学習率に勾配を掛けた値を引くことで更新します。
重み に関する損失関数 を可視化しましょう。勾配が正(傾き )の場合は、逆方向(負の方向)に移動したいので、各イテレーションで を負の方向に更新します。イテレーションが完了すると、重みは理想的にはコスト関数を最小化する値になります。
実際には、これらのコスト関数はこのように凸ではなく、数十万のパラメータに依存します。モメンタムを加えたりオプティマイザを変えたりするなど、この険しいコスト地形を乗り越えるための工夫がありますが、今日はそこまで扱いません。また、スキップ接続を含めるなどネットワークの構造を変えて最適化を改善する方法もあります。これらのスキップ接続は残差ネットワークで使われ、多層ネットワークの最適化を可能にします。
# @markdown Execute this cell to view gradient descent gif
from IPython.display import Image
Image(url='https://github.com/NeuromatchAcademy/course-content/blob/main/tutorials/static/grad_descent.gif?raw=true')損失関数を減らすために重みを修正するために、勾配降下法 (GD) アルゴリズムを使います。これは3つのステップを繰り返すものです。
- トレーニングデータ上で損失を評価します。
out = net(train_data)
loss = loss_fn(out, train_labels)
ここで、train_data はトレーニングデータのネットワーク入力(今回の場合は神経応答)、train_labels は各入力に対応するターゲット出力(今回の場合は真の刺激の向き)です。
2. ネットワークの各重みに関して損失の勾配を計算します。PyTorchでは、損失 loss の .backward() メソッドでこれができます。勾配は各イテレーションで蓄積されるため、.backward() を呼ぶ前に勾配をクリアする必要があります。これは組み込みのオプティマイザの .zero_grad() メソッドで行います。まとめると
optimizer.zero_grad()
loss.backward()
- 勾配に沿ってネットワークの重みを更新します。PyTorchの組み込みオプティマイザを使います。ここでは
optim.SGDオプティマイザを使います(ドキュメントはこちら)。これは学習率でスケールされた負の勾配方向にパラメータを更新します。初期化時に
- どのパラメータを更新するか
- どの学習率を使うか
を指定します。
例えば、学習率0.001でネットワーク net のすべてのパラメータを最適化するには、次のように初期化します。
optimizer = optim.SGD(net.parameters(), lr=.001)
ここで .parameters() は nn.Module クラスのメソッドで、このクラスのすべてのパラメータ(今回の場合は )を返すPythonジェネレータオブジェクトです。
ステップ2で全パラメータの勾配を計算した後、オプティマイザの .step() メソッドで各パラメータを更新します。
optimizer.step()
次の演習では、GDアルゴリズムを実装するためのコード骨格を提供します。空欄を埋めるのがあなたの仕事です。
GDアルゴリズムの数学的詳細はボーナスセクション2.1を参照してください。
ここでは、すべてのトレーニングデータに対して一度に勾配を計算するため、勾配降下法(確率的勾配降下法ではありません)を使っています。通常はトレーニングデータが多すぎるため、例えば神経応答を20刺激ずつのセットに分けて処理します。深層学習におけるエポックとは、すべてのトレーニングデータをネットワークに順伝播・逆伝播させる1回の処理を指します。ここでは20エポック分の順伝播・逆伝播を実行しますが、実際のトレーニングでは数千エポックが必要なこともあります。
確率的勾配降下法の詳細な議論はボーナスセクション2.2を参照してください。
コーディング演習 3.2: PyTorchでの勾配降下法
勾配降下法アルゴリズムを使って与えられたネットワークの重みを最適化する関数 train() を完成させてください。この関数は以下の引数を取ります。
net: 重みを最適化するPyTorchのネットワークloss_fn: 損失を評価するためのPyTorchの損失関数train_data: 損失を評価するためのトレーニングデータ(すなわちデコード対象の神経応答)train_labels:train_dataの各データ点に対応するターゲット出力(すなわち真の刺激の向き)
この関数を実行すると、裏でPyTorchがネットワーク内のパラメータを変更してネットワークのデコード性能を向上させるため、初期化時とは異なる重みになります。
def train(net, loss_fn, train_data, train_labels,
n_epochs=50, learning_rate=1e-4):
"""Run gradient descent to optimize parameters of a given network
Args:
net (nn.Module): PyTorch network whose parameters to optimize
loss_fn: built-in PyTorch loss function to minimize
train_data (torch.Tensor): n_train x n_neurons tensor with neural
responses to train on
train_labels (torch.Tensor): n_train x 1 tensor with orientations of the
stimuli corresponding to each row of train_data
n_epochs (int, optional): number of epochs of gradient descent to run
learning_rate (float, optional): learning rate to use for gradient descent
Returns:
(list): training loss over iterations
"""
# Initialize PyTorch SGD optimizer
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
# Placeholder to save the loss at each iteration
train_loss = []
# Loop over epochs
for i in range(n_epochs):
######################################################################
## TO DO for students: fill in missing code for GD iteration
raise NotImplementedError("Student exercise: write code for GD iterations")
######################################################################
# compute network output from inputs in train_data
out = ... # compute network output from inputs in train_data
# evaluate loss function
loss = loss_fn(out, train_labels)
# Clear previous gradients
...
# Compute gradients
...
# Update weights
...
# Store current value of loss
train_loss.append(loss.item()) # .item() needed to transform the tensor output of loss_fn to a scalar
# Track progress
if (i + 1) % (n_epochs // 5) == 0:
print(f'iteration {i + 1}/{n_epochs} | loss: {loss.item():.3f}')
return train_loss
# Set random seeds for reproducibility
np.random.seed(1)
torch.manual_seed(1)
# Initialize network with 10 hidden units
net = DeepNetReLU(n_neurons, 10)
# Initialize built-in PyTorch MSE loss function
loss_fn = nn.MSELoss()
# Run gradient descent on data
train_loss = train(net, loss_fn, resp_train, stimuli_train)
# Plot the training loss over iterations of GD
plot_train_loss(train_loss)出力例:
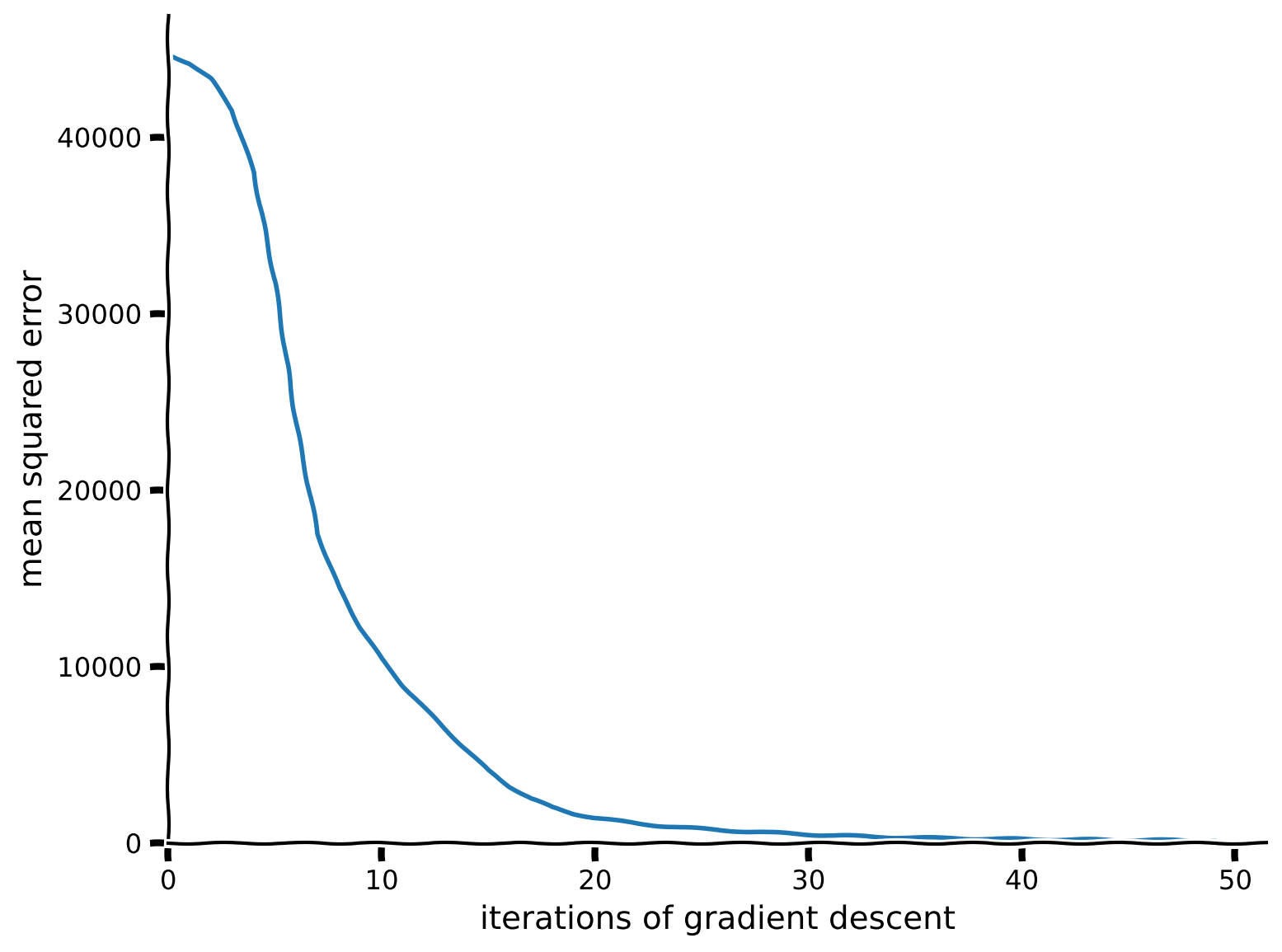
# @title Submit your feedback
content_review(f"{feedback_prefix}_Gradient_descent_in_Pytorch_Exercise")モデルをさらに改善することができます。時間があるときにチュートリアルのボーナス部分をご覧ください。ここでは、重みの可視化、テストデータでの性能評価、新しい損失関数への切り替え、正則化の追加などを通じてモデルの性能を評価し改善する方法を詳しく説明しています。
まとめ
チュートリアルの推定所要時間: 1時間20分
これまでに、神経データからのデコードに深層学習を適用するための一般的かつ強力な手法をいくつか紹介しました。これらの手法の中には、ほぼすべての機械学習問題に共通するものもあります:
- PyTorch の
nn.Moduleクラスと組み込みの最適化アルゴリズムを使った深層ネットワークの構築と学習 - 損失関数の選択
このチュートリアルで重要だったのは、コーディング演習3.2で作成した train() 関数です。この関数は、任意のネットワークを、任意の損失関数に対して、任意の訓練データで最小化するために使えます。これがPyTorchを使ってニューラルネットワーク、さらには他のどんなモデルでも学習できる強みです!nn.Module クラスには、ニューラルネットワークの操作を実装する nn.Linear レイヤーを使わなければならないという制約はありません。このクラスの .__init__() と .forward() メソッドの中に、パラメータと計算がすべて torch.Tensor に関わり、モデルが微分可能であれば、何でも入れることができます。そうすれば、このモデルのパラメータを、ここで行った深層ネットワークの最適化と全く同じ方法で最適化できます。
この種の解析からどのような結論が導けるでしょうか?視覚野の活動から刺激をうまくデコードできるなら、その刺激に関する情報が視覚野に存在することを意味します。しかし、動物がその情報を意思決定に使っているかどうかは、このような解析からはわかりません。実際、マウスはサルやヒトに比べて方向識別課題の成績が悪いですが、視覚野にはこれらの刺激に関する情報があります。なぜマウスは方向識別課題で成績が悪いと思いますか?
いくつかの仮説については Stringer, et al., 2021 を参照してくださいが、これは完全に未解決の問題です!
ボーナス
ボーナスセクション1: ニューラルネットワークの深さ、幅、および表現力
ここで使ったような深層フィードフォワードネットワークを構築する際に常に決定しなければならない重要なアーキテクチャの選択肢は以下の2つです:
- 隠れ層の数、すなわちネットワークの深さ
- 各層のユニット数、すなわち層の幅
ここでは幅の単一隠れ層のネットワークに限定しましたが、このコードを任意の深さに適応するのは簡単です。隠れ層をもう1つ追加するには、__init__() メソッドにもう1つ nn.Linear モジュールを追加し、.forward() メソッドに組み込めばよいだけです。
ネットワークの深さと幅は、ネットワークが実行できる入力/出力変換の集合、すなわち表現力を決定します。ネットワークが深く幅広いほど、より表現力が高くなり、計算可能な入力/出力変換のクラスが大きくなります。実際、無限に幅広いまたは無限に深いネットワークは原理的に(ほぼ)任意の入力/出力変換を計算できる$ことが知られています。
深さの力を示す古典的な数学的例は、いわゆるXOR問題です。このおもちゃ問題は、隠れ層がない浅いネットワークに比べて、単一隠れ層でもネットワークが実行できる入力/出力変換の集合を劇的に拡大できることを示しています。重要な直感は、隠れ層が入力を新しい形式で表現できるようにし、それによってほぼ何でもできるようになるということです。この隠れ層が幅広いほど、この表現の柔軟性が増します。特に、隠れユニット数が入力ユニット数より多い場合、隠れ層の入力表現は元のデータ表現より高次元になります。この高次元性は、任意の計算を行うための「空間」を実質的に増やします。実際、この単一隠れ層だけでも十分に幅広くすれば、任意の入力/出力変換を近似できます。これについてはこちらの視覚的なデモが参考になります。
しかし実際には、深さを増やすほうが幅を増やすよりも少ないユニット数でより高い表現力を与えるようです(その理由はよくわかっていません)。このため、機械学習では本当に深いネットワークがほぼ常に使われており、この技術群は深層学習と呼ばれています。
とはいえ、ネットワークを深く幅広くするにはコストもあります。ネットワークが大きくなるほど、最適化すべきパラメータ(重みやバイアス)が増えます。幅や深さを増やすことで得られる追加の表現力には少なくとも2つの問題が伴います:
- パラメータが増えると通常、より多くのデータが必要になる
- パラメータ数が多いネットワークは訓練データに過剰適合しやすくなるため、一般化を保証するためにより高度な最適化アルゴリズムが必要になる
ボーナスセクション2: 勾配降下法
ボーナスセクション2.1: 勾配降下法の方程式
ここでは、デコード問題に適用した勾配降下法アルゴリズムの3つのステップの方程式を示します:
- 訓練データ上で損失を評価します。平均二乗誤差損失の場合、損失は次のように表されます:
ここで、 は訓練データの番目の刺激に対する集団応答 からデコードされた刺激の向き、 はその刺激の真の向きです。 は訓練セットのデータサンプル総数を表します。上記の train() 関数の構文では、 は train_data[n, :]、 は train_labels[n] に対応します。
- ネットワークの各重みについて損失の勾配を計算します。ここでは、次の量を計算します:
通常、これらの勾配を導出するには多くの数学とコードが必要ですが、PyTorchが助けてくれます!自動微分$という技術を使い、.backward() 関数を呼び出すとPyTorchが自動的にこれらの勾配を計算します。
具体的には、この関数を特定の変数(例えば上記の loss)に対して呼ぶと、PyTorchは各ネットワークパラメータに関する勾配を計算し、内部で保存します。これらは各パラメータの .grad 属性からアクセス可能です。ただし、上で見たように、勾配降下法を実装する際にこれらの勾配を直接参照したり呼び出したりする必要はなく、optim.SGD のようなPyTorch組み込みの最適化器がこれを処理します。
- 勾配に沿ってネットワークの重みを更新します:
\begin{align}
& \
& \
& \
&\leftarrow \mathbf{b}^{out} - \alpha \frac{\partial L}{\partial \mathbf{b}^{out}}
\end{align}
ここで、 は学習率と呼ばれます。これはSGDアルゴリズムのハイパーパラメータで、各反復で勾配に沿ってどれだけパラメータを更新するかを制御します。反復回数を減らすためにできるだけ大きくすべきですが、損失関数の最小値を飛び越えないように大きすぎてはいけません。
ここに示した方程式はこのチュートリアルで扱ったネットワークと損失関数に特有のものですが、上で示した3ステップを実装するコードは完全に一般的です。どんな損失関数やネットワークでも、同じコマンドでこれらの3ステップを実装できます。
勾配の計算方法は逆伝播法と呼ばれます。損失関数は:
\begin{align}
L &= (y - \
&= (\mathbf{W}^{out} \mathbf{h} - \tilde{y})^2
\end{align}
ここで、、 は活性化関数(例えばRELU)です。
は式の外側にあるため計算が簡単です(この場合はベクトルなので標準的な微分です):
次に連鎖律を使って に関する微分を計算します。RELU活性化関数 のため、出力が正のときのみ正の値になります。連鎖律のために損失の に関する微分が必要です:
したがって、
\begin{align}
&= \begin{cases}
& \
0 & \text{otherwise}
\end{cases} \
&= \begin{cases}
2 & \
0 & \text{otherwise}
\end{cases}
\end{align}
ここで注意すべきは:
はアダマール積(要素ごとの積)を表し、 は活性化関数の微分です。RELUの場合:
\begin{align}
&= \begin{cases}
1 & \
0 & \text{otherwise}
\end{cases}
\end{align}
最後の層の微分を1回計算し、次の層の微分を1回計算して前の層の微分と掛け合わせるという連鎖律を使うことで、効率的に計算できます。これらの操作は比較的高速で、深層ネットワークの学習を可能にしています。
loss.backward() コマンドは、定義された loss に関して各ネットワークパラメータの勾配を計算します。この計算は自動微分$を使って行われ、逆伝播法を実装しています。ネットワークの大きさに関わらず動作し、PyTorchで構築された任意の深層ネットワークモデルの勾配降下法を可能にします。
ボーナスセクション2.2: 確率的勾配降下法(SGD)と勾配降下法(GD)の違い
このチュートリアルでは勾配降下法(GD)を使いましたが、これはより一般的に使われる確率的勾配降下法(SGD)とは微妙かつ重要な違いがあります。主な違いは各反復の最初のステップで、GDでは訓練セットのすべてのデータサンプルで損失を評価しますが、SGDでは訓練セットのランダムなサブセットであるミニバッチだけで損失を評価します。各反復でランダムにミニバッチをサンプリングし、ステップ1~3を実行します。上記の方程式はすべて成り立ちますが、 個のデータサンプル は訓練セット全体ではなくミニバッチのランダムなサンプルを指します。
SGDを使う理由はいくつかあります。まず、訓練セットが大きすぎてすべてのデータサンプルで損失を評価できない場合です。この場合、GDは実行不可能なので、メモリ負荷を軽減するために訓練セットを小さなミニバッチに分割して処理するSGDを使うしかありません。
しかしGDが可能な場合でも、SGDのほうがしばしば優れています。SGDのランダムサンプリングによる確率的性質は、損失関数の局所最小値探索にノイズを加えます。これにより局所最小値に陥るのを避け、収束する最小値が良いものになるよう促します。これは特にネットワークが幅広く深い場合に重要で、多数のパラメータが過剰適合を引き起こしやすいためです。
ここでは、(1) シンプルであること、(2) ここで扱う問題に十分であることからGDのみを使いました。データセットに多数のニューロンがいるため、デコードはそれほど難しくなく、特に深く幅広いネットワークを必要としません。したがって、深層ネットワークのパラメータ数が少なく、GDでも問題なく最適化できます。