![]()

チュートリアル 2: 分類器と正則化
第1週 第3日目: 一般化線形モデル
Neuromatch Academyによる
コンテンツ作成者: Pierre-Etienne H. Fiquet, Ari Benjamin, Jakob Macke
コンテンツレビュアー: Davide Valeriani, Alish Dipani, Michael Waskom, Ella Batty
制作編集者: Spiros Chavlis
チュートリアルの目的
チュートリアルの推定所要時間: 1時間35分
これは一般化線形モデル(GLM)に関する2部構成のシリーズのパート2です。GLMは教師あり学習の基本的な枠組みです。パート1ではGLMについて学び、実装しました。このチュートリアルでは、GLMの特別なケースであるロジスティック回帰を実装します。ロジスティック回帰は二値の結果をモデル化するために使われます。
予測したい変数が2つの値のいずれかしか取らないことがよくあります。左か右か?起きているか眠っているか?車かバスか?このチュートリアルでは、マウスの左/右の意思決定をスパイク列データからデコードします。目的は以下の通りです:
- ロジスティック回帰について、そのGLM理論内での導出方法とscikit-learnでの実装方法を学ぶ
- ロジスティック回帰を用いて神経応答から選択をデコードする
- 正則化について、異なるアプローチとハイパーパラメータの影響を学ぶ
Steinmetz et al., 2019 によるデータの共有に感謝します。本チュートリアルではその一部を使用しています。
# @title Tutorial slides
# @markdown These are the slides for the videos in all tutorials today
from IPython.display import IFrame
link_id = "upyjz"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)セットアップ
# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W1D3_T2"# Imports
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score# @title Figure settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
import ipywidgets as widgets
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")# @title Plotting Functions
def plot_weights(models, sharey=True):
"""Draw a stem plot of weights for each model in models dict."""
n = len(models)
f = plt.figure(figsize=(10, 2.5 * n))
axs = f.subplots(n, sharex=True, sharey=sharey)
axs = np.atleast_1d(axs)
for ax, (title, model) in zip(axs, models.items()):
ax.margins(x=.02)
stem = ax.stem(model.coef_.squeeze())
stem[0].set_marker(".")
stem[0].set_color(".2")
stem[1].set_linewidths(.5)
stem[1].set_color(".2")
stem[2].set_visible(False)
ax.axhline(0, color="C3", lw=3)
ax.set(ylabel="Weight", title=title)
ax.set(xlabel="Neuron (a.k.a. feature)")
f.tight_layout()
plt.show()
def plot_function(f, name, var, points=(-10, 10)):
"""Evaluate f() on linear space between points and plot.
Args:
f (callable): function that maps scalar -> scalar
name (string): Function name for axis labels
var (string): Variable name for axis labels.
points (tuple): Args for np.linspace to create eval grid.
"""
x = np.linspace(*points)
ax = plt.figure().subplots()
ax.plot(x, f(x))
ax.set(
xlabel=f'${var}$',
ylabel=f'${name}({var})$'
)
plt.show()
def plot_model_selection(C_values, accuracies):
"""Plot the accuracy curve over log-spaced C values."""
ax = plt.figure().subplots()
ax.set_xscale("log")
ax.plot(C_values, accuracies, marker="o")
best_C = C_values[np.argmax(accuracies)]
ax.set(
xticks=C_values,
xlabel="C",
ylabel="Cross-validated accuracy",
title=f"Best C: {best_C:1g} ({np.max(accuracies):.2%})",
)
plt.show()
def plot_non_zero_coefs(C_values, non_zero_l1, n_voxels):
"""Plot the accuracy curve over log-spaced C values."""
ax = plt.figure().subplots()
ax.set_xscale("log")
ax.plot(C_values, non_zero_l1, marker="o")
ax.set(
xticks=C_values,
xlabel="C",
ylabel="Number of non-zero coefficients",
)
ax.axhline(n_voxels, color=".1", linestyle=":")
ax.annotate("Total\n# Neurons", (C_values[0], n_voxels * .98), va="top")
plt.show()#@title Data retrieval and loading
import os
import requests
import hashlib
url = "https://osf.io/r9gh8/download"
fname = "W1D4_steinmetz_data.npz"
expected_md5 = "d19716354fed0981267456b80db07ea8"
if not os.path.isfile(fname):
try:
r = requests.get(url)
except requests.ConnectionError:
print("!!! Failed to download data !!!")
else:
if r.status_code != requests.codes.ok:
print("!!! Failed to download data !!!")
elif hashlib.md5(r.content).hexdigest() != expected_md5:
print("!!! Data download appears corrupted !!!")
else:
with open(fname, "wb") as fid:
fid.write(r.content)
def load_steinmetz_data(data_fname=fname):
with np.load(data_fname) as dobj:
data = dict(**dobj)
return dataセクション1: ロジスティック回帰
# @title Video 1: Logistic regression
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'qfXFrUnLU0o'), ('Bilibili', 'BV1P54y1q7Qn')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Logistic_regression_Video")ロジスティック回帰は二値分類モデルです。これはロジスティックリンク関数とベルヌーイ(コイン投げ)ノイズモデルを持つGLMです。
前回のノートブックと同様に、ロジスティック回帰は標準的な手順を踏みます:
- 入力と出力の関係を表すモデルを定義する。
- モデルに基づくデータの(対数)確率を最大化するようパラメータを調整する。
セクション1.1: ロジスティック回帰モデル
チュートリアル開始からここまでの推定時間:8分
動画の関連部分のテキスト要約はこちらをクリック
ロジスティック回帰の基本的な入出力の式は以下の通りです:
ここで、ロジスティック回帰の出力 は、入力 とパラメータ が与えられたときの y=1 である確率 と解釈します。
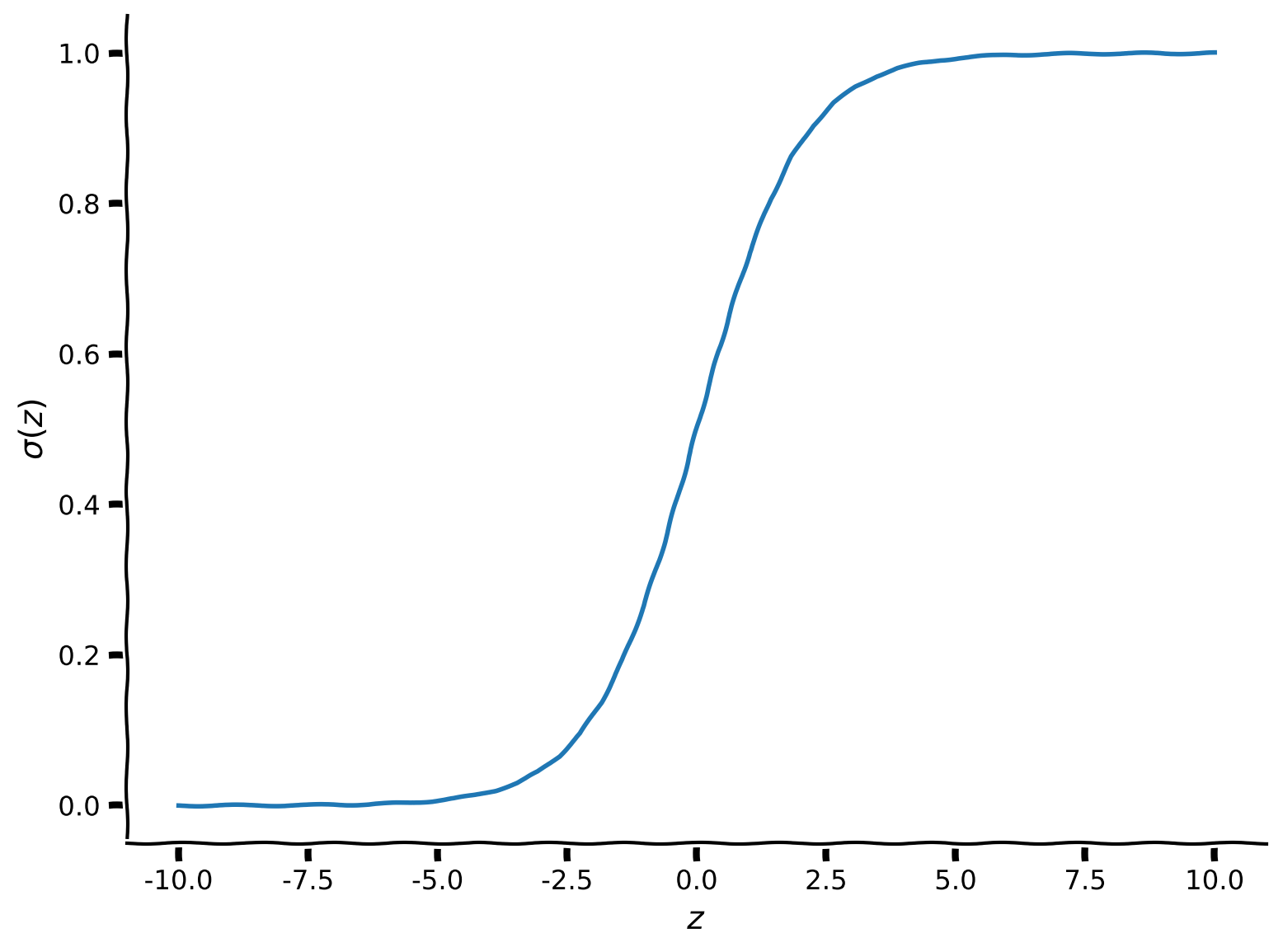
は「圧縮」関数で、シグモイド関数またはロジスティック関数と呼ばれます。その出力は の範囲にあります。形は以下の通りです:
ここで です。パラメータによって が非常に負の値になると 、非常に正の値になると となります。
コーディング演習 1.1: シグモイド関数を実装しよう
def sigmoid(z):
"""Return the logistic transform of z."""
##############################################################################
# TODO for students: Fill in the missing code (...) and remove the error
raise NotImplementedError("Student exercise: implement the sigmoid function")
##############################################################################
sigmoid = ...
return sigmoid
# Visualize
plot_function(sigmoid, "\sigma", "z", (-10, 10))出力例:
# @title Submit your feedback
content_review(f"{feedback_prefix}_Implement_the_sigmoid_function_Exercise")セクション1.2: scikit-learnの利用
チュートリアル開始からここまでの推定時間:13分
前回のノートブックとは異なり、今回はロジスティック回帰モデル全体を自分で実装するのではなく、機械学習で非常に人気のあるライブラリ scikit-learn の実装を使います。
このセクションの目的は、scikit-learn の分類器を紹介し、実際の神経データに適用する方法を理解することです。
セクション2: ロジスティック回帰による神経データのデコード
セクション2.1: データの準備
チュートリアル開始からここまでの推定時間:15分
このノートブックでは、以前に見たSteinmetzデータセットを使用します。このデータセットには、マウスが意思決定課題を行う際のニューロンの記録が含まれています。
マウスは、ガボール刺激が左か右か、あるいは全くないかを示すためにホイールを回す課題を行いました。ニューロピクセルプローブで皮質全体のスパイクが計測されています。以下はBiorXivプレプリントからの課題の模式図です。
# @markdown Execute to see schematic
import IPython
IPython.display.Image("http://kordinglab.com/images/others/steinmetz-task.png")本日はロジスティック回帰を使って神経データから意思決定をデコードします。マウスが「左」または「右」を選択した試行のみを考慮し、NoGo試行は無視します。
データ形式
隠された「データ取得と読み込み」セルにはデータを読み込む関数があります:
spikes: 正規化されたスパイク率の配列で形状は(n_trials, n_neurons)choices: 0と1のベクトルで、動物の行動応答を示し、長さはn_trialsです。
data = load_steinmetz_data()
for key, val in data.items():
print(key, val.shape)前回のチュートリアルで見たGLM(線形回帰やポアソン回帰)と同様に、2つのデータ構造が必要です:
- 形状が
(n_samples, n_features)のX行列 - 長さが
n_samplesのyベクトル
前回のノートブックでは、y が神経データに対応し、X は実験に関する何かでした。ここではその関係を逆にします。これがデコードモデルの特徴で、神経応答 (X) から行動 (y) を予測します。
y = data["choices"]
X = data["spikes"]セクション2.2: モデルの適合
チュートリアル開始からここまでの推定時間:25分
scikit-learn のロジスティック回帰モデルの使用は非常に簡単です。
# Define the model
log_reg = LogisticRegression(penalty=None)
# Fit it to data
log_reg.fit(X, y)ここでは2つのステップがあります:
- ハイパーパラメータ(どのペナルティを使うか)を指定してモデルを初期化する(ノートブック後半で詳しく扱います)
Xとyを渡してモデルを適合させる
セクション2.3: 訓練データの分類
チュートリアル開始からここまでの推定時間:27分
モデルの適合は最尤推定を行い、一連の特徴重みを学習します。学習した重みを使って新しいデータを分類したり、各サンプルのラベルを予測したりできます。
y_pred = log_reg.predict(X)セクション2.4: モデルの評価
チュートリアル開始からここまでの推定時間:30分
次にモデルの予測を評価します。ここでは正解率を用います。分類器の正解率は、予測ラベルが真のラベルと一致した試行の割合で決まります。
コーディング演習 2.4: 分類器の正解率
最初の演習として、正解率スコアを使って分類器を評価する関数を実装してください。それを使って訓練データに対する分類器の正解率を求めます。
def compute_accuracy(X, y, model):
"""Compute accuracy of classifier predictions.
Args:
X (2D array): Data matrix
y (1D array): Label vector
model (sklearn estimator): Classifier with trained weights.
Returns:
accuracy (float): Proportion of correct predictions.
"""
#############################################################################
# TODO Complete the function, then remove the next line to test it
raise NotImplementedError("Implement the compute_accuracy function")
#############################################################################
y_pred = model.predict(X)
accuracy = ...
return accuracy
# Compute train accuracy
train_accuracy = compute_accuracy(X, y, log_reg)
print(f"Accuracy on the training data: {train_accuracy:.2%}")以下のように表示されるはずです
訓練データに対する正解率: 100.00%
# @title Submit your feedback
content_review(f"{feedback_prefix}_Classifier_accuracy_Video")セクション2.5: 分類器の交差検証
チュートリアル開始からここまでの推定時間:40分
訓練データに対する分類精度は100%です!これは一見すごいように思えますが、昨日学んだ過学習の概念を思い出してください。分類器は訓練データの特異な特徴を学習してしまっている可能性があります。その場合、真のデータ→意思決定関数を学習しておらず、新しいデータに対してはうまく一般化できません。
これを確認するために、交差検証による正解率を評価します。
# @markdown Execute to see schematic
import IPython
IPython.display.Image("http://kordinglab.com/images/others/justCV-01.png")scikit-learn のヘルパー関数を使った交差検証
昨日は交差検証を自分で実装する関数を書いてもらいましたが、実際には scikit-learn はこれを簡単に行うための多くの便利な関数$を提供しています。例えば、cross_val_score を使って分類器の交差検証ができます。
cross_val_score は LogisticRegression のような sklearn モデルと X, y のデータを受け取り、訓練/テスト分割でモデルを再学習し、各テストセットでの正解率を返します。
accuracies = cross_val_score(LogisticRegression(penalty=None), X, y, cv=8) # k=8 cross validation# @markdown Run to plot out these `k=8` accuracy scores.
f, ax = plt.subplots(figsize=(8, 3))
ax.boxplot(accuracies, vert=False, widths=.7)
ax.scatter(accuracies, np.ones(8))
ax.set(
xlabel="Accuracy",
yticks=[],
title=f"Average test accuracy: {accuracies.mean():.2%}"
)
ax.spines["left"].set_visible(False)
plt.show()訓練データに対する正解率(100%)に比べて交差検証による正解率が低いことは、モデルが過学習していることを示唆しています。これは驚くべきことではありません。 行列の形状を考えてみてください:
print(X.shape)モデルの特徴数はサンプル数のほぼ3倍あります。このような状況では過学習が非常に起こりやすい(ほぼ確実に起こる)です。
神経科学との関連: 神経データでは特徴数がサンプル数を上回ることがよくあります。ニューロン数が独立試行数より多い場合や、fMRIデータで測定ボクセル数が独立試行数より多い場合などが例です。
なぜ特徴量がサンプル数より多いと過学習になるのか
簡単に言うと、特徴量がサンプル数より多いとモデル推定の分散が大きくなります。つまり、新しいデータを得て .fit() を実行するたびに、まったく異なるモデルが得られてしまうのです。これは、1日目に学んだバイアス/分散トレードオフと非常に関連しています。
なぜこうなるのでしょうか?直感を掴むために小さな例を考えてみましょう。2次元空間で最適な直線を見つけようとしているとき、データ点が1つしかなければ、その点を通る直線は無限に存在します。これが、特徴量がサンプル数より多い場合に直面する状況です。
それに対してできること
1日目に学んだように、モデルの分散を減らすにはバイアスを増やすことを受け入れればよいのです。ここでは、正しいパラメータはすべて小さいと仮定してバイアスを増やします。2次元の例で言えば、すべての直線の中で水平線を好むようなものです。これが正則化の一例です。
セクション3: 正則化
チュートリアル開始からここまでの推定時間: 50分
# @title Video 2: Regularization
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'b2IaUCZ91bo'), ('Bilibili', 'BV1Tg4y1i773')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Regularization_Video")ビデオのテキスト要約はこちらをクリック
正則化は、モデルにあらかじめ正しいと信じる解を学習させることで、トレーニングデータの特異性に過度に適合することを防ぎます。これによりモデルのバイアスは増えますが、パラメータは小さいかほぼ0であるべきだと(おそらく)知っているため、良いバイアスとなります。
GLM(一般化線形モデル)では、よく使われる正則化の形として分類器の重みを縮小する方法があります。線形モデルでは、重みをプロットすることでその効果を確認できます。このセクションでは、plot_weights というヘルパー関数を多用します。
正則化なしのロジスティック回帰モデルの重みは次のようになります。
log_reg = LogisticRegression(penalty=None).fit(X, y)
plot_weights({"No regularization": log_reg})このプロットを理解することが重要です。各点はパラメータベクトル の値を可視化しています。(ビデオで示された のプロットと同じスタイルです)。各特徴量はニューロンの時間平均応答なので、各点はモデルが意思決定を推定するために各ニューロンをどのように使っているかを示しています。
y軸のスケールに注目してください。あるニューロンは約 の値を持ち、他のニューロンは までスケールしています。
セクション3.1: 正則化
チュートリアル開始からここまでの推定時間: 53分
正則化にはさまざまな種類があります。非常に一般的なものは または「リッジ」ペナルティです。これは目的関数を次のように変えます。
ここで は正則化の強さを決めるハイパーパラメータです。
scikit-learn では penalty を変えることで正則化を使え、C ハイパーパラメータで正則化の強さを設定できます( なので、これは逆正則化強度を設定します)。
正則化なしの分類器の重みと、デフォルトの C = 1 を使ったときの重みを比較してみましょう。
log_reg_l2 = LogisticRegression(penalty="l2", C=1).fit(X, y)
# now show the two models
models = {
"No regularization": log_reg,
"$L_2$ (C = 1)": log_reg_l2,
}
plot_weights(models)同じy軸のスケールを使うと の重みはほとんど見えません。y軸のスケールをそれぞれの重みに合わせて調整してみましょう。
plot_weights(models, sharey=False)これで重みは基本的に同じパターンですが、正則化された重みは1桁小さいことがわかります。
インタラクティブデモ 3.1: を変えたときのパラメータサイズへの影響
同じ方法で、正則化の強さが重みにどう影響するかを見てみましょう。
# @markdown Execute this cell to enable the widget!
# Precompute the models so the widget is responsive
log_C_steps = 1, 11, 1
penalized_models = {}
for log_C in np.arange(*log_C_steps, dtype=int):
m = LogisticRegression("l2", C=10 ** log_C, max_iter=5000)
penalized_models[log_C] = m.fit(X, y)
@widgets.interact
def plot_observed(log_C = widgets.IntSlider(value=1, min=1, max=10, step=1)):
models = {
"No regularization": log_reg,
f"$L_2$ (C = $10^{{{log_C}}}$)": penalized_models[log_C]
}
plot_weights(models)上記の通り なので、 が大きいほど正則化は弱くなります。上のパネルは に対応します。
セクション3.2: 正則化
チュートリアル開始からここまでの推定時間: 1時間3分
正則化には だけでなく、 または「ラッソ」ペナルティもあります。これは目的関数を次のように変えます。
実際には、重みの絶対値の和を使うことでスパース性が生まれます。つまり、単に小さくなるだけでなく、一部の重みは強制的に になります。
log_reg_l1 = LogisticRegression(penalty="l1", C=1, solver="saga", max_iter=5000)
log_reg_l1.fit(X, y)
models = {
"$L_2$ (C = 1)": log_reg_l2,
"$L_1$ (C = 1)": log_reg_l1,
}
plot_weights(models)注意: ここでは solver="saga" と max_iter=5000 という2つの追加パラメータを指定しています。LogisticRegression クラスは複数の最適化アルゴリズム("ソルバー")を使えますが、すべてが ペナルティをサポートしているわけではありません。ある時点でソルバーは最小値を見つけられなければ諦めます。max_iter は試行回数を増やすパラメータで、これがないと「収束しない」という警告が出ることがあります。
セクション3.3: と 正則化の重要な違い:スパース性
チュートリアル開始からここまでの推定時間: 1時間10分
と のどちらを使うべきでしょうか?どちらのペナルティもパラメータを縮小し、過学習を減らすのに役立ちますが、結果として得られるモデルは異なります。
特に、 ペナルティはほとんどのパラメータが0になるスパースな解を促します。スパース性の概念を説明しましょう。
「密な」ベクトルはほとんどの要素が非ゼロです:
。
「スパース」なベクトルはほとんどの要素がゼロです:
。
行列でも同様です。
# @markdown Execute to plot a dense and a sparse matrix
np.random.seed(50)
n = 5
M = np.random.random((n, n))
M_sparse = np.random.choice([0, 1], size=(n, n), p=[0.8, 0.2])
fig, axs = plt.subplots(1, 2, sharey=True, figsize=(10, 5))
axs[0].imshow(M)
axs[1].imshow(M_sparse)
axs[0].axis('off')
axs[1].axis('off')
axs[0].set_title("A dense matrix", fontsize=15)
axs[1].set_title("A sparse matrix", fontsize=15)
text_kws = dict(ha="center", va="center")
for i in range(n):
for j in range(n):
iter_parts = axs, [M, M_sparse], ["{:.1f}", "{:d}"]
for ax, mat, fmt in zip(*iter_parts):
val = mat[i, j]
color = ".1" if val > .7 else "w"
ax.text(j, i, fmt.format(val), c=color, **text_kws)
plt.show()コーディング演習 3.3: 正則化がパラメータのスパース性に与える影響
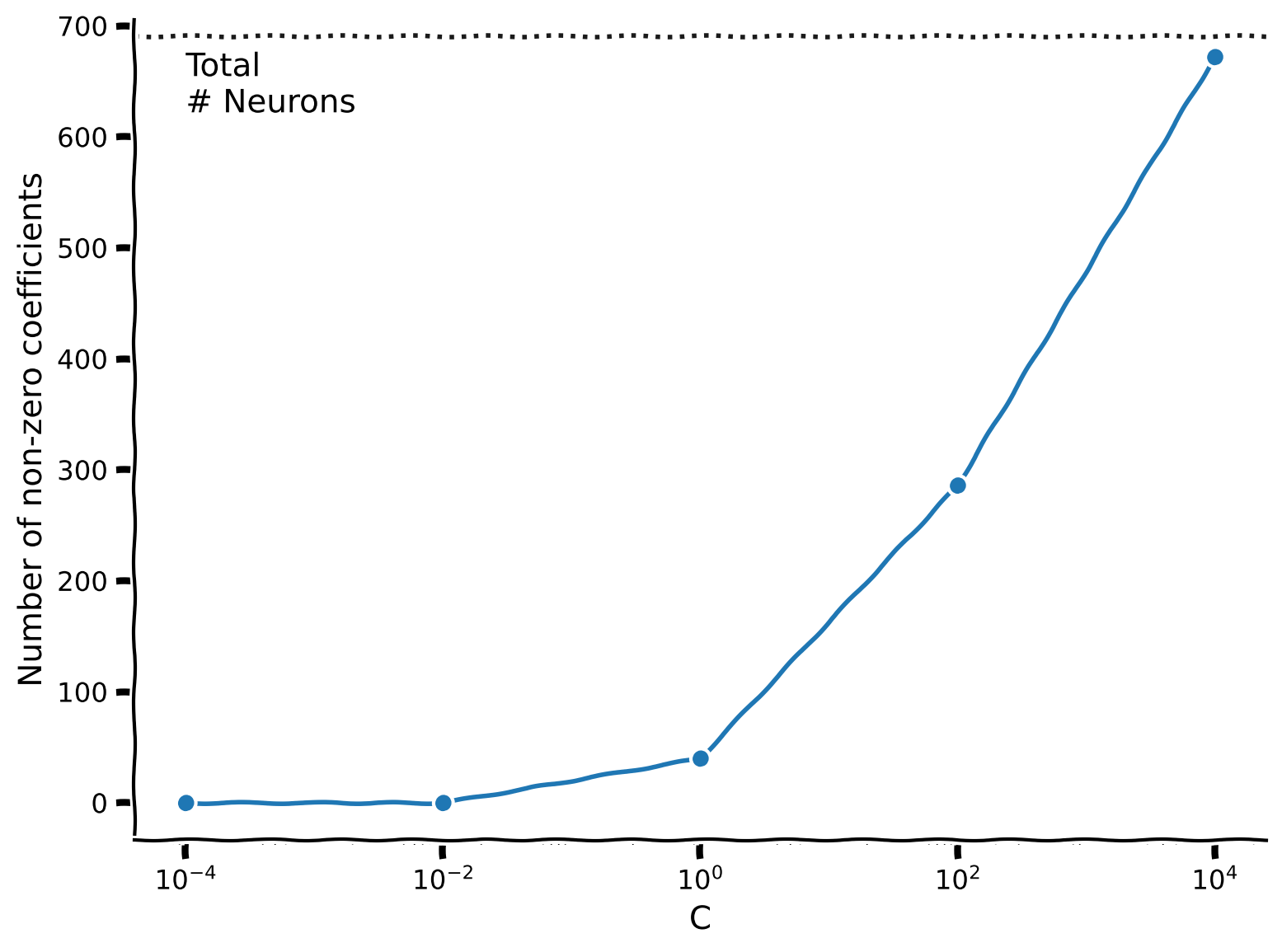
以下の関数を完成させて、正則化された LogisticRegression モデルをフィットし、パラメータベクトルの中で0になっている係数の数を返してください。
scikit-learnのドキュメント$もぜひ参照してください。
def count_non_zero_coefs(X, y, C_values):
"""Fit models with different L1 penalty values and count non-zero coefficients.
Args:
X (2D array): Data matrix
y (1D array): Label vector
C_values (1D array): List of hyperparameter values
Returns:
non_zero_coefs (list): number of coefficients in each model that are nonzero
"""
#############################################################################
# TODO Complete the function and remove the error
raise NotImplementedError("Implement the count_non_zero_coefs function")
#############################################################################
non_zero_coefs = []
for C in C_values:
# Initialize and fit the model
# (Hint, you may need to set max_iter)
model = ...
...
# Get the coefs of the fit model (in sklearn, we can do this using model.coef_)
coefs = ...
# Count the number of non-zero elements in coefs
non_zero = ...
non_zero_coefs.append(non_zero)
return non_zero_coefs
# Use log-spaced values for C
C_values = np.logspace(-4, 4, 5)
# Count non zero coefficients
non_zero_l1 = count_non_zero_coefs(X, y, C_values)
# Visualize
plot_non_zero_coefs(C_values, non_zero_l1, n_voxels=X.shape[1])出力例:
# @title Submit your feedback
content_review(f"{feedback_prefix}_Effect_of_L1_on_sparsity_Exercise")が小さい( が大きい)ほどスパースな解になります。
神経科学へのリンク:パラメータベクトルがスパースであると仮定してよいのはどんな場合でしょうか?ほとんどの特徴量が結果に影響しない場合です。例えば、全脳fMRIから低レベルの視覚特徴をデコードする場合、予測に使われるのはV1や視床のボクセルだけだと予想されるかもしれません。
注意: を解釈するときは注意してください。非ゼロの係数を持つボクセルやニューロンだけが結果に情報を持つという証拠として解釈してはいけません。これは正則化の結果であり、解がスパースであるという我々の事前仮定の産物です。別の正則化やモデルでは脳全体に分散した関係性を見つけるかもしれません。モデルの仮定に基づく現象を、そのモデルの証拠として使うのは避けてください。
セクション3.4: 正則化ペナルティの選択
チュートリアル開始からここまでの推定時間: 1時間25分
これまでの例では、正則化の強さを適当に選びました。ハイパーパラメータの値はどうやって決めればよいでしょうか?
答えは、良いパラメータ値を学習できたかどうかを知りたいときと同じです:クロスバリデーションを使います。最適なハイパーパラメータは、未知のデータに最もよく一般化できるものです。
コーディング演習 3.4: モデル選択
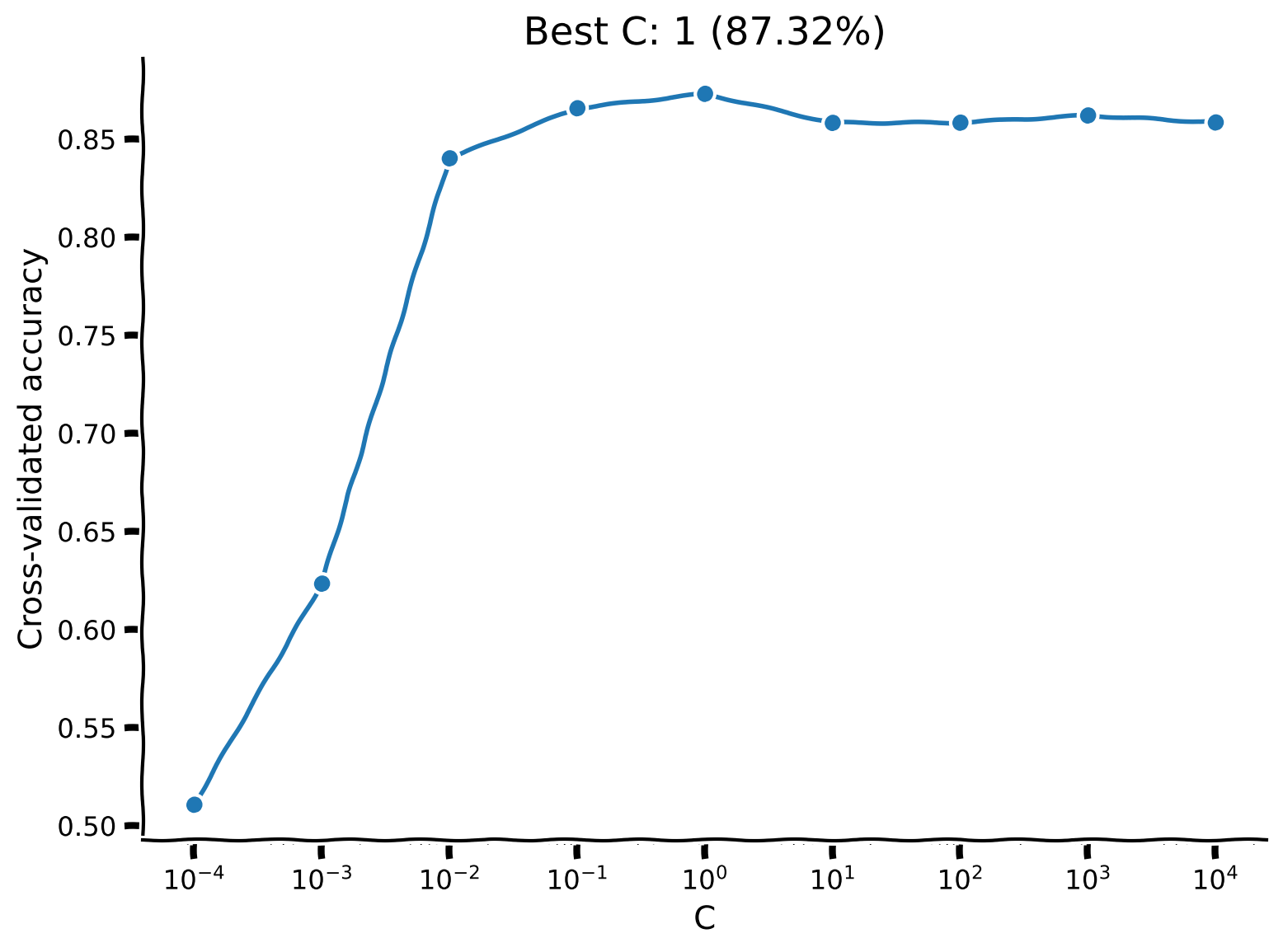
最後の演習では、異なる ペナルティを持つ複数のモデルをクロスバリデーションで評価します。model_selection 関数には、各ペナルティ値に対して平均クロスバリデーション精度を取得するforループを実装してください(上で紹介した cross_val_score 関数を8分割で使います)。
def model_selection(X, y, C_values):
"""Compute CV accuracy for each C value.
Args:
X (2D array): Data matrix
y (1D array): Label vector
C_values (1D array): Array of hyperparameter values
Returns:
accuracies (1D array): CV accuracy with each value of C
"""
#############################################################################
# TODO Complete the function and remove the error
raise NotImplementedError("Implement the model_selection function")
#############################################################################
accuracies = []
for C in C_values:
# Initialize and fit the model
# (Hint, you may need to set max_iter)
model = ...
# Get the accuracy for each test split using cross-validation
accs = ...
# Store the average test accuracy for this value of C
accuracies.append(...)
return accuracies
# Use log-spaced values for C
C_values = np.logspace(-4, 4, 9)
# Compute accuracies
accuracies = model_selection(X, y, C_values)
# Visualize
plot_model_selection(C_values, accuracies)出力例:
# @title Submit your feedback
content_review(f"{feedback_prefix}_Model_selection_Exercise")このプロットは、 の適切な値が重要であることを示唆しています。ただしある程度までです。 は逆正則化強度であることを思い出してください。正則化が強すぎる( が小さい)モデルは非常に性能が悪いです。 では差はわずかですが、最良の性能は中間の値()で得られました。
まとめ
チュートリアルの推定時間: 1時間35分
このノートブックでは、分類の基本アルゴリズムであるロジスティック回帰について学びました。動物の行動選択を神経活動から予測する神経デコーディング問題に適用しました。複雑なモデルは過学習のリスクがあるため、クロスバリデーションで評価することの重要性を再確認し、正則化によってより良く一般化するモデルをフィットできることを学びました。最後に、正則化のさまざまな選択肢について学び、クロスバリデーションがモデル選択に役立つことを示しました。
記号の説明
\begin{align}
x &\
y &\
&\
&\
C &\
&\
&\
&\
&\
&\
\end{align}
ボーナス
ボーナスセクション1: ロジスティック回帰モデルの完全な式
ロジスティック回帰の基本的な入出力の式は次の通りです。
ロジスティックリンク関数
は見たことがあると思いますが、 は新しいものです。これはシグモイドまたはロジスティックリンク関数で、 を0から1の間に「押し込む」関数です:
ベルヌーイ尤度
シグモイドの出力 は0か1の二値ではないことに気づいたかもしれません。実際のデータ は二値ですが、 は y=1 である確率 と解釈します:
パラメータの尤度を得るには、 を与えられたときの の確率を定義する必要があります。ロジスティック回帰ではベルヌーイ分布を使います:
回帰モデルを代入すると:
この式はパラメータ の良さを測っています。データが独立であると仮定して、パラメータの尤度として書くと:
これを最適化の対象とし、すべての試行で和を取ると:
ボーナスセクション2: モデル選択の詳細
最後の演習では、すべてのデータを使ってハイパーパラメータを選びました。つまり、選択したモデルの性能を評価するための新しいデータは残っていません。実際には、モデルの選択や学習に関与しなかったデータで最終評価を行うネストされたクロスバリデーションを2層に分けて行うべきです。
実際、ハイパーパラメータ選択のためのデータ分割方法は混乱しやすいです。ここに、機械学習を神経デコーディングに使うチュートリアルを執筆中に著者が作成したガイドがあります。arxiv:1708.00909
# @markdown Execute to see schematic
import IPython
IPython.display.Image("http://kordinglab.com/images/others/CV-01.png")