![]()

チュートリアル 1: 離散状態の最適制御
ボーナス: 最適制御
Neuromatch Academyによる
コンテンツ作成者: Zhengwei Wu, Itzel Olivos Castillo, Shreya Saxena, Xaq Pitkow
コンテンツレビュアー: Karolina Stosio, Roozbeh Farhoodi, Saeed Salehi, Ella Batty, Spiros Chavlis, Matt Krause, Michael Waskom, Melisa Maidana Capitan
制作編集者: Gagana B, Spiros Chavlis
チュートリアルの目的
推定所要時間: 60分
このチュートリアルでは、二値制御タスクを実装します。これは釣りを表す部分観測マルコフ決定過程(POMDP)です。エージェント(あなた)は、魚の群れがどこにいるかを直接観察できない状態で、2つの釣り場から報酬を得ようとします(はい、魚の群れは「スクール」と呼ばれます!)。これにより、世界はHidden Dynamicsの日と同様に隠れマルコフモデル(HMM)となります。いつどこで魚を捕まえたかに基づいて、過去の観測に基づく魚の位置の事後分布、すなわち信念を更新し続けます。あなたは、サイドを切り替えるコストを最小限に抑えつつ、最も多くの魚を獲得するように位置を制御すべきです。
これまでに確率的ダイナミクス、潜在状態、観測について学びました。最初の演習はこれらの復習が中心です。ここで新たに行動を導入し、制御、効用、方策の新しい概念に基づきます。この一般的な構造は、動物が情報を収集し、環境について推論し、最大の利益をもたらす行動を選択できる知覚-行動ループを含むため、脳の計算の基礎モデルを提供します。ニューロンがこれらの計算をどのように実装するかは別の問題であり、このレッスンでは扱いません。
このチュートリアルであなたは:
- 以前学んだ隠れマルコフモデルを使って世界の状態をモデル化する。
- 観測(捕まえた魚)を使って魚の位置に関する信念(事後分布)を構築する。
- 行動選択のための異なる制御方策の質を評価する。
- 効用を最大化する方策を発見する。
# @title Tutorial slides
# @markdown These are the slides for all videos in this tutorial.
from IPython.display import IFrame
link_id = "8j5rs"
print(f"If you want to download the slides: https://osf.io/download/{link_id}/")
IFrame(src=f"https://mfr.ca-1.osf.io/render?url=https://osf.io/{link_id}/?direct%26mode=render%26action=download%26mode=render", width=854, height=480)セットアップ
# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_cn",
"user_key": "y1x3mpx5",
},
).render()
feedback_prefix = "W3D3_T1"# Imports
import numpy as np
from math import isclose
import matplotlib.pyplot as plt# @title Figure Settings
import logging
logging.getLogger('matplotlib.font_manager').disabled = True
import ipywidgets as widgets
from IPython.display import HTML
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")# @title Plotting Functions
def plot_fish(fish_state, ax=None, show=True):
"""
Plot the fish dynamics (states across time)
"""
T = len(fish_state)
offset = 3
if not ax:
fig, ax = plt.subplots(1, 1, figsize=(12, 3.5))
x = np.arange(0, T, 1)
y = offset * (fish_state*2 - 1)
ax.plot(y, color='cornflowerblue', markersize=10, linewidth=3.0, zorder=0)
ax.fill_between(x, y, color='cornflowerblue', alpha=.3)
ax.set_xlabel('time')
ax.set_ylabel('fish location')
ax.set_xlim([0, T])
ax.set_xticks([])
ax.xaxis.set_label_coords(1.05, .54)
ax.set_ylim([-(offset+.5), offset+.5])
ax.set_yticks([-offset, offset])
ax.set_yticklabels(['left', 'right'])
ax.spines['bottom'].set_position('center')
if show:
plt.show()
def plot_measurement(measurement, ax=None, show=True):
"""
Plot the measurements
"""
T = len(measurement)
rel_pos = 3
red_y = []
blue_y = []
for idx, value in enumerate(measurement):
if value == 0:
blue_y.append([idx, -rel_pos])
else:
red_y.append([idx, rel_pos])
red_y = np.asarray(red_y)
blue_y = np.asarray(blue_y)
if not ax:
fig, ax = plt.subplots(1, 1, figsize=(12, 3.5))
if len(red_y) > 0:
ax.plot(red_y[:, 0], red_y[:, 1], '*', markersize=8, color='crimson')
if len(blue_y) > 0:
ax.plot(blue_y[:, 0], blue_y[:, 1], '*', markersize=8, color='royalblue')
ax.set_xlabel('time', fontsize=18)
ax.set_ylabel('Caught fish?')
ax.set_xlim([0, T])
ax.set_xticks([])
ax.xaxis.set_label_coords(1.05, .54)
ax.set_ylim([-rel_pos - .5, rel_pos + .5])
ax.set_yticks([-rel_pos, rel_pos])
ax.set_yticklabels(['no', 'yes!'])
ax.spines['bottom'].set_position('center')
if show:
plt.show()
def plot_act_loc(loc, act, ax_loc=None, show=True):
"""
Plot the action and location of T time points
"""
T = len(act)
if not ax_loc:
fig, ax_loc = plt.subplots(1, 1, figsize=(12, 2.5))
loc = loc*2 - 1
act_down = []
act_up = []
for t in range(1, T):
if loc[t-1] == -1 and loc[t] == 1:
act_up.append([t - 0.5, 0])
if loc[t-1] == 1 and loc[t] == -1:
act_down.append([t - 0.5, 0])
act_down = np.array(act_down)
act_up = np.array(act_up)
ax_loc.plot(loc, 'g.-', markersize=8, linewidth=5)
if len(act_down) > 0:
ax_loc.plot(act_down[:, 0], act_down[:, 1], 'rv', markersize=18, zorder=10, label='switch')
if len(act_up) > 0:
ax_loc.plot(act_up[:, 0], act_up[:, 1], 'r^', markersize=18, zorder=10)
ax_loc.set_xlabel('time')
ax_loc.set_ylabel('Your state')
ax_loc.set_xlim([0, T])
ax_loc.set_xticks([])
ax_loc.xaxis.set_label_coords(1.05, .54)
if len(act_down) > 0:
ax_loc.legend(loc="upper right")
elif len(act_down) == 0 and len(act_up) > 0:
ax_loc.plot(act_up[:, 0], act_up[:, 1], 'r^', markersize=18, zorder=10, label='switch')
ax_loc.legend(loc="upper right")
ax_loc.set_ylim([-1.1, 1.1])
ax_loc.set_yticks([-1, 1])
ax_loc.tick_params(axis='both', which='major')
ax_loc.set_yticklabels(['left', 'right'])
ax_loc.spines['bottom'].set_position('center')
if show:
plt.show()
def plot_belief(belief, ax1=None, choose_policy=None, show=True):
"""
Plot the belief dynamics of T time points
"""
T = belief.shape[1]
if not ax1:
fig, ax1 = plt.subplots(1, 1, figsize=(12, 2.5))
ax1.plot(belief[1, :], color='midnightblue', markersize=10, linewidth=3.0)
ax1.set_xlabel('time')
ax1.set_ylabel('Belief (right)')
ax1.set_xlim([0, T])
ax1.set_xticks([])
ax1.xaxis.set_label_coords(1.05, 0.05)
ax1.set_yticks([0, 1])
ax1.set_ylim([0, 1.1])
labels = [item.get_text() for item in ax1.get_yticklabels()]
ax1.set_yticklabels([' 0', ' 1'])
"""
if choose_policy == "threshold":
ax2 = ax1.twinx()
ax2.plot(time_range, threshold * np.ones(time_range.shape), 'r--')
ax2.plot(time_range, (1 - threshold) * np.ones(time_range.shape), 'c--')
ax2.set_yticks([threshold, 1 - threshold])
ax2.set_ylim([0, 1.1])
ax2.tick_params(axis='both', which='major', labelsize=18)
labels = [item.get_text() for item in ax2.get_yticklabels()]
labels[0] = 'threshold to switch \n from left to right'
labels[-1] = 'threshold to switch \n from right to left'
ax2.set_yticklabels(labels)
"""
if show:
plt.show()
def plot_dynamics(belief, loc, act, meas, fish_state, choose_policy):
"""
Plot the dynamics of T time points
"""
if choose_policy == 'threshold':
fig, [ax0, ax_bel, ax_loc, ax1] = plt.subplots(4, 1, figsize=(12, 9))
plot_fish(fish_state, ax=ax0, show=False)
plot_belief(belief, ax1=ax_bel, show=False)
plot_measurement(meas, ax=ax1, show=False)
plot_act_loc(loc, act, ax_loc=ax_loc)
else:
fig, [ax0, ax_bel, ax1] = plt.subplots(3, 1, figsize=(12, 7))
plot_fish(fish_state, ax=ax0, show=False)
plot_belief(belief, ax1=ax_bel, show=False)
plot_measurement(meas, ax=ax1, show=False)
plt.tight_layout()
plt.show()
def belief_histogram(belief, bins=100):
"""
Plot the histogram of belief states
"""
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
ax.hist(belief, bins)
ax.set_xlabel('belief', fontsize=18)
ax.set_ylabel('count', fontsize=18)
plt.show()
def plot_value_threshold(threshold_array, value_array):
"""
Helper function to plot the value function and threshold
"""
yrange = np.max(value_array) - np.min(value_array)
star_loc = np.argmax(value_array)
fig_, ax = plt.subplots(1, 1, figsize=(8, 6))
ax.plot(threshold_array, value_array, 'b')
ax.vlines(threshold_array[star_loc],
min(value_array) - yrange * .1, max(value_array),
colors='red', ls='--')
ax.plot(threshold_array[star_loc],
value_array[star_loc],
'*', color='crimson',
markersize=20)
ax.set_ylim([np.min(value_array) - yrange * .1,
np.max(value_array) + yrange * .1])
ax.set_title(f'threshold vs value with switching cost c = {cost_sw:.2f}',
fontsize=20)
ax.set_xlabel('threshold', fontsize=16)
ax.set_ylabel('value', fontsize=16)
plt.show()# @title Helper Functions
# To generate a binomial with fixed "noise",
# we generate a fist sequence of T numbers uniformly at random
# this sequence can be changed later with different size T
np.random.seed(42)
init_T = 100
rnd_tele = np.random.uniform(0, 1, init_T)
rnd_high_rwd = np.random.uniform(0, 1, init_T)
rnd_low_rwd = np.random.uniform(0, 1, init_T)
def get_randomness(T):
global rnd_tele
global rnd_high_rwd
global rnd_low_rwd
rnd_tele = np.random.uniform(0, 1, T)
rnd_high_rwd = np.random.uniform(0, 1, T)
rnd_low_rwd = np.random.uniform(0, 1, T)
def binomial_tele(p, T):
if len(rnd_tele) < T:
get_randomness(T)
return np.array([1 if p > rnd_tele[i] else 0 for i in range(T)])
# Need a better name
def getRandomness(p, T):
global rnd_tele
global rnd_high_rwd
global rnd_low_rwd
rnd_tele = np.random.uniform(0, 1, T)
rnd_high_rwd = np.random.uniform(0, 1, T)
rnd_low_rwd = np.random.uniform(0, 1, T)
return [binomial_tele(p, T), rnd_high_rwd, rnd_low_rwd]
class ExcerciseError(AssertionError):
pass
class binaryHMM():
def __init__(self, params, T, fish_initial=0, loc_initial=0):
self.params = params
self.fish_initial = fish_initial
self.loc_initial = loc_initial
self.T = T
def fish_dynamics(self):
"""
fish state dynamics according to telegraph process
Returns:
fish_state (numpy array of int)
"""
p_stay, _, _, _ = self.params
fish_state = np.zeros(self.T, int) # 0: left side and 1: right side
# initialization
fish_state[0] = self.fish_initial
tele_operations = binomial_tele(p_stay, self.T) # 0: switch and 1: stay
for t in range(1, self.T):
# we use logical operation NOT XOR to determine the next state
fish_state[t] = int(not(fish_state[t-1] ^ tele_operations[t]))
return fish_state
def generate_process_lazy(self):
"""
fish dynamics and rewards if you always stay in the initial location
without changing sides
Returns:
fish_state (numpy array of int): locations of the fish
loc (numpy array of int): left or right site, 0 for left, and 1 for right
rwd (numpy array of binary): whether a fish was caught or not
"""
_, p_low_rwd, p_high_rwd, _ = self.params
fish_state = self.fish_dynamics()
rwd = np.zeros(self.T, int) # 0: no food, 1: get food
for t in range(0, self.T):
# new measurement
if fish_state[t] != self.loc_initial:
rwd[t] = 1 if p_low_rwd > rnd_low_rwd[t] else 0
else:
rwd[t] = 1 if p_high_rwd > rnd_high_rwd[t] else 0
# rwd[t] = binomial(1, p_rwd_vector[(fish_state[t] == loc[t]) * 1])
return fish_state, self.loc_initial*np.ones(self.T), rwd
class binaryHMM_belief(binaryHMM):
def __init__(self, params, T,
fish_initial=0, loc_initial=1,
choose_policy='threshold'):
binaryHMM.__init__(self, params, T, fish_initial, loc_initial)
self.choose_policy = choose_policy
def generate_process(self):
"""
fish dynamics and measurements based on the chosen policy
Returns:
belief (numpy array of float): belief on the states of the two sites
act (numpy array of string): actions over time
loc (numpy array of int): left or right site
measurement (numpy array of binary): whether a reward is obtained
fish_state (numpy array of int): fish locations
"""
p_stay, low_rew_p, high_rew_p, threshold = self.params
fish_state = self.fish_dynamics() # 0: left side; 1: right side
loc = np.zeros(self.T, int) # 0: left side, 1: right side
measurement = np.zeros(self.T, int) # 0: no food, 1: get food
act = np.empty(self.T, dtype='object') # "stay", or "switch"
belief = np.zeros((2, self.T), float) # the probability that the fish is on the left (1st element)
# or on the right (2nd element),
# the beliefs on the two boxes sum up to be 1
rew_prob = np.array([low_rew_p, high_rew_p])
# initialization
loc[0] = self.loc_initial
measurement[0] = 0
belief_0 = np.random.random(1)[0]
belief[:, 0] = np.array([belief_0, 1 - belief_0])
act[0] = self.policy(threshold, belief[:, 0], loc[0])
for t in range(1, self.T):
if act[t - 1] == "stay":
loc[t] = loc[t - 1]
else:
loc[t] = int(not(loc[t - 1] ^ 0))
# new measurement
# measurement[t] = binomial(1, rew_prob[(fish_state[t] == loc[t]) * 1])
if fish_state[t] != loc[t]:
measurement[t] = 1 if low_rew_p > rnd_low_rwd[t] else 0
else:
measurement[t] = 1 if high_rew_p > rnd_high_rwd[t] else 0
belief[0, t] = self.belief_update(belief[0, t - 1] , loc[t],
measurement[t], p_stay,
high_rew_p, low_rew_p)
belief[1, t] = 1 - belief[0, t]
act[t] = self.policy(threshold, belief[:, t], loc[t])
return belief, loc, act, measurement, fish_state
def policy(self, threshold, belief, loc):
"""
chooses policy based on whether it is lazy policy
or a threshold-based policy
Args:
threshold (float): the threshold of belief on the current site,
when the belief is lower than the threshold, switch side
belief (numpy array of float): the belief on the two sites
loc (int) : the location of the agent
Returns:
act (string): "stay" or "switch"
"""
if self.choose_policy == "threshold":
act = policy_threshold(threshold, belief, loc)
if self.choose_policy == "lazy":
act = policy_lazy(belief, loc)
return act
def belief_update(self, belief_past, loc, measurement, p_stay,
high_rew_p, low_rew_p):
"""
using PAST belief on the LEFT box, CURRENT location and
and measurement to update belief
"""
rew_prob_matrix = np.array([[1 - high_rew_p, high_rew_p],
[1 - low_rew_p, low_rew_p]])
# update belief posterior, p(s[t] | measurement(0-t), act(0-t-1))
belief_0 = (belief_past * p_stay + (1 - belief_past) * (1 - p_stay)) *\
rew_prob_matrix[(loc + 1) // 2, measurement]
belief_1 = ((1 - belief_past) * p_stay + belief_past * (1 - p_stay)) *\
rew_prob_matrix[1-(loc + 1) // 2, measurement]
belief_0 = belief_0 / (belief_0 + belief_1)
return belief_0
def policy_lazy(belief, loc):
"""
This function is a lazy policy where stay is also taken
"""
act = "stay"
return act
def test_policy_threshold():
well_done = True
for loc in [-1, 1]:
threshold = 0.4
belief = np.array([.2, .3])
if policy_threshold(threshold, belief, loc) != "switch":
raise ExcerciseError("'policy_threshold' function is not correctly implemented!")
for loc in [1, -1]:
threshold = 0.6
belief = np.array([.7, .8])
if policy_threshold(threshold, belief, loc) != "stay":
raise ExcerciseError("'policy_threshold' function is not correctly implemented!")
print("Well Done!")
def test_policy_threshold():
for loc in [-1, 1]:
threshold = 0.4
belief = np.ones(2) * (threshold + 0.1)
belief[(loc + 1) // 2] = threshold - 0.1
if policy_threshold(threshold, belief, loc) != "switch":
raise ExcerciseError("'policy_threshold' function is not correctly implemented!")
if policy_threshold(threshold, belief, -1 * loc) != "stay":
raise ExcerciseError("'policy_threshold' function is not correctly implemented!")
print("Well Done!")
def test_value_function():
measurement = np.array([0, 0, 0, 1, 0, 0, 0, 0, 1, 1])
act = np.array(["switch", "stay", "switch", "stay", "stay",
"stay", "switch", "switch", "stay", "stay"])
cost_sw = .5
if not isclose(get_value(measurement, act, cost_sw), .1):
raise ExcerciseError("'value_function' function is not correctly implemented!")
print("Well Done!")セクション 1: 問題の分析
# @title Video 1: Gone fishing
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', '3oIwUFpolVA'), ('Bilibili', 'BV1FL411p7o5')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Gone_fishing_Video")問題設定
1. 状態のダイナミクス: 魚の位置は左か右の2つの可能性があります。秘密裏に、各時間ステップで魚は一定の確率 で左右を切り替えます。これはLinear Systemsの日に見た二値スイッチングモデル(テレグラフ過程)です。魚の位置 は潜在変数であり、魚を捕まえようとしたときに得られる観測により情報が得られます。これにより、過去の観測に基づく現在の位置の事後確率、すなわち信念が得られます。
2. 行動: 過去の日とは異なり、今度はプロセスに行動を起こせます!現在の位置(左または右)に留まるか、反対側に移動することができます。
3. 報酬とコスト: 捕まえた魚1匹につき1「ポイント」の報酬が得られます。魚と同じ側にいる場合、離散時間ステップごとに確率 で魚を捕まえられます。そうでない場合でも確率 で魚を捕まえられることがあります。
反対側に移動すると ポイントのコストがかかります。賢く決めましょう!
効用の最大化
賢く決めて総効用(総ポイント)を最大化するために、どんな状況でも何をすべきかを示す方策に従います。ここで状況はあなたの位置と魚の位置に関する信念 (事後分布)で決まります(魚の位置は潜在変数であることを思い出してください)。
最適制御理論では、信念は過去のすべての観測に基づく潜在変数の事後確率です。この事後に関して期待効用を最大化することが最適であることが示されています。
本問題では、魚は左か右のどちらかにいるため信念は1つの数値で表せます。すなわち:
ここで は観測、 は行動(留まるか切り替えるか)です。
最後に、方策は信念に基づく単純な閾値でパラメータ化します:魚が現在いる側にいる確率が閾値 を下回ったら反対側に切り替えます。
このチュートリアルで、適切な閾値を選べばこの単純な方策が最適であることを発見します!
インタラクティブデモ 1: 魚のダイナミクスの観察
このデモでは、魚が左右に動くダイナミクスを、あなたが一箇所に留まったまま観察します。魚が同じ場所に留まる確率 stay_prob を操作し、魚の動きの様子を観察してください。
考える質問:
- 魚が長い間一方の側にいる場合、魚が反対側に移る確率は変わるでしょうか?
- どの値の p_stay のときに魚の位置は最も予測しやすく、また最も予測しにくいでしょうか?
# @markdown Execute this cell to enable the demo.
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(p_stay=widgets.FloatSlider(.9, description="stay_prob", min=0., max=1., step=0.01))
def update_ex_1(p_stay):
"""
T: Length of timeline
p_stay: probability that the fish do not swim to the other side at time t
"""
params = [p_stay, _, _, _]
# initial condition: fish [fish_initial] start at the left location (-1)
binaryHMM_test = binaryHMM(params=params, fish_initial=1, T=100)
fish_state = binaryHMM_test.fish_dynamics()
plot_fish(fish_state)
plt.show()# @title Submit your feedback
content_review(f"{feedback_prefix}_Examining_fish_dynamics_Interactive_Demo_and_Discussion")セクション 2: 魚を捕まえる
# @title Video 2: Catch some fish
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'ZjB2_SAY2uE'), ('Bilibili', 'BV1kD4y1m7Lo')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Catch_some_fish_Video")インタラクティブデモ 2: 報酬関数の観察
この2つ目のデモでは、ボタンであなたの位置を制御しますが、魚の位置は stay_prob = 1 に固定します。魚が一箇所で穏やかに泳いでいる状態で、魚と同じ側にいるときと反対側にいるときの報酬を視覚的に確認します。
魚と同じ側にいるときは魚を捕まえる確率が高くなるはずです(ただし、スライダーを操作して他の条件に変えることも技術的には可能です!)。
スライダー high_rew_prob(魚と同じ側にいるときの高い報酬確率)と low_rew_prob(反対側にいるときの低い報酬確率)を操作してください。ボタン(同じ場所 vs. 違う場所)が魚を捕まえる確率を決めます。
考える質問:
- 魚とエージェント(あなた!)が同じ場所にいる場合と異なる場所にいる場合、何が起きますか?
- どこで最も多く魚を捕まえられますか?
- なぜ
low_rew_prob + high_rew_prob = 1ではないのでしょう?これらの確率は釣りの物語で何を意味していますか? - スライダーを動かして
low_rew_prob > high_rew_probにすることもできます。これは数学的には変わりませんが、物理的な問題の合理的なモデルかどうかは変わるかもしれません。なぜでしょう?
# @markdown Execute this cell to enable the demo.
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(locs=widgets.RadioButtons(options=['same location', 'different locations'],
description='Fish and agent:',
disabled=False,
layout={'width': 'max-content'}),
p_low_rwd=widgets.FloatSlider(.1, description="low_rew_prob:",
min=0., max=1.),
p_high_rwd=widgets.FloatSlider(.9, description="high_rew_prob:",
min=0., max=1.))
def update_ex_2(locs, p_low_rwd, p_high_rwd):
"""
p_stay: probability of fish staying at current side at time t
p_low_rwd: probability of catching fish when you're NOT on the side where the fish are swimming
p_high_rwd: probability of catching fish when you're on the side where the fish are swimming
fish_initial: initial side of fish (-1 left, 1 right)
agent_initial: initial side of the agent (YOU!) (-1 left, 1 right)
"""
p_stay = 1
params = [p_stay, p_low_rwd, p_high_rwd, _]
# initial condition for fish [fish_initial] and you [loc_initial]
if locs == 'same location':
binaryHMM_test = binaryHMM(params, fish_initial=0, loc_initial=0, T=100)
else:
binaryHMM_test = binaryHMM(params, fish_initial=1, loc_initial=0, T=100)
fish_state, loc, measurement = binaryHMM_test.generate_process_lazy()
plot_measurement(measurement)# @title Submit your feedback
content_review(f"{feedback_prefix}_Examining_the_reward_function_Interactive_Demo_and_Discussion")セクション 3: 信念のダイナミクスと信念分布
# @title Video 3: Where are the fish?
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'rmETVsRFYGk'), ('Bilibili', 'BV19t4y1Q7VH')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Where_are_the_fish_Video")インタラクティブデモ 3: 信念の観察
ここで、信念がどのように計算されるかの直感を得ましょう。ここでの信念は、観測に基づく魚の位置の事後確率 です。これはHidden Dynamicsの日に行ったことと同じです!
この演習では、あなたは常に左側に留まりますが、魚は動き回ります。魚は確率 stay_prob で同じ側に留まります。魚の群れの位置は見えず、捕まえた魚だけが観測です。これらの観測を使って魚の群れの位置を推定します。
デモではスライダー high_rew_prob、low_rew_prob、stay_prob を操作してください。
考える質問:
-
stay_probのスライダーを操作してみてください。魚が一箇所に留まる確率を変えると、信念は魚のダイナミクスをどれほど説明できますか? -
極端な場合、
high_rew_prob = 1かつlow_rew_prob = 0のとき、信念の精度はどう変わりますか? -
どんな条件で魚を捕まえることが情報的でしょうか?魚を捕まえないことはどうでしょう?
# @markdown Execute this cell to enable the demo.
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(p_stay=widgets.FloatSlider(.96, description="stay_prob",
min=.8, max=1., step=.01),
p_low_rwd=widgets.FloatSlider(.1, description="low_rew_prob",
min=0., max=1., step=.01),
p_high_rwd=widgets.FloatSlider(.3, description="high_rew_prob",
min=0., max=1., step=.01))
def update_ex_2(p_stay, p_low_rwd, p_high_rwd):
"""
T: Length of timeline
p_stay: probability of fish staying at current side at time t
p_high_rwd: probability of catching fish when you're on the side where the fish are swimming
p_low_rwd: probability of catching fish when you're NOT on the side where the fish are swimming
fish_initial: initial side of fish (0 left, 1 right)
agent_initial: initial side of the agent (YOU!) (0 left, 1 right)
threshold: threshold of belief below which the action is switching
"""
threshold = 0.2
params = [p_stay, p_low_rwd, p_high_rwd, threshold]
binaryHMM_test = binaryHMM_belief(params, choose_policy="lazy",
fish_initial=0, loc_initial=0, T=100)
belief, loc, act, measurement, fish_state = binaryHMM_test.generate_process()
plot_dynamics(belief, loc, act, measurement, fish_state,
binaryHMM_test.choose_policy)# @title Submit your feedback
content_review(f"{feedback_prefix}_Examining_the_beliefs_Interactive_Demo_and_Discussion")セクション 4: 閾値方策の実装
# @title Video 4: How should you act?
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'cTzaQl2Vxn4'), ('Bilibili', 'BV1ri4y137cj')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_How_should_you_act_Video")コーディング演習 4: 閾値ベース ポリシーに従う動的挙動
ここでは、上で使った「怠け者」ポリシーから、あなたが実装する閾値ポリシーに切り替えます。信念が十分に低くて魚がいる側にいると判断したら、位置を変えます。関数 policy_threshold(threshold, belief, loc) を更新してください。このポリシーは3つの入力を取ります:
-
魚の状態に関する
belief(信念)。便宜上、時刻 t における信念は2次元ベクトルで表します。1つ目の要素は魚が左にいる信念、2つ目は魚が右にいる信念です。各時刻でこれらの要素は合計1になります。 -
あなたの位置
locは「左」= -1、「右」= 1 で表します。 -
スイッチするかどうかを決める信念の
threshold(閾値)。魚と同じ側にいる信念がこの閾値を下回ったら、反対側に移動し、それ以外はそのまま留まります。
関数は各時刻 t に対して、「stay」または「switch」のいずれかの行動を返すようにしてください。
def policy_threshold(threshold, belief, loc):
"""
chooses whether to switch side based on whether the belief
on the current site drops below the threshold
Args:
threshold (float): the threshold of belief on the current site,
when the belief is lower than the threshold, switch side
belief (numpy array of float, 2-dimensional): the belief on the
two sites at a certain time
loc (int) : the location of the agent at a certain time
-1 for left side, 1 for right side
Returns:
act (string): "stay" or "switch"
"""
############################################################################
## 1. Modify the code below to generate actions (stay or switch)
## for current belief and location
##
## Belief is a 2d vector: first element = Prob(fish on Left | measurements)
## second element = Prob(fish on Right | measurements)
## Returns "switch" if Belief that fish are in your current location < threshold
## "stay" otherwise
##
## Hint: use loc value to determine which row of belief you need to use
## see the docstring for more information about loc
##
## 2. After completing the function, comment this line:
raise NotImplementedError("Student exercise: Please complete the code")
############################################################################
# Write the if statement
if ...:
# action below threshold
act = ...
else:
# action above threshold
act = ...
return act
# Next line tests your function
test_policy_threshold()ご覧ください
よくできました!
# @title Submit your feedback
content_review(f"{feedback_prefix}_Dynamics_threshold_based_policy_Exercise")インタラクティブデモ 4: 異なる閾値での動的挙動
以下のデモは、あなたが作成したポリシーを使っています!スライダーを操作して、ポリシーで制御される動的挙動を観察してください。
(コードでは stay_prob=0.95、high_rew_prob=0.3、low_rew_prob=0.1 と指定しています。これらは変更可能ですが、妥当なパラメータです。注意:閾値の変化を段階的に見るには同じ乱数を使い続けてください。異なる例を見たい場合はシードをリフレッシュしてください。)
考える質問:
- このポリシーは魚をどの程度うまく追えているでしょうか?何を見逃していて、その理由は?
- 閾値が非常に低い場合や非常に高い場合、釣り戦略はどのように特徴づけられますか?
# @markdown Execute this cell to enable the demo.
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(threshold=widgets.FloatSlider(.2, description="threshold", min=0., max=1., step=.01),
new_seed=widgets.ToggleButtons(options=['Reusing', 'Refreshing'],
description='Random seed:',
disabled=False,
button_style='', # 'success', 'info', 'warning', 'danger' or '',
icons=['check'] * 2
))
def update_ex_4(threshold, new_seed):
"""
p_stay: probability fish stay
high_rew_p: p(catch fish) when you're on their side
low_rew_p : p(catch fish) when you're on other side
threshold: threshold of belief below which switching is taken
"""
if new_seed == "Refreshing":
get_randomness(T=100)
stay_prob=.95
high_rew_p=.3
low_rew_p=.1
params = [stay_prob, high_rew_p, low_rew_p, threshold]
# initial condition for fish [fish_initial] and you [loc_initial]
binaryHMM_test = binaryHMM_belief(params, fish_initial=0, loc_initial=0, choose_policy="threshold", T=100)
belief, loc, act, measurement, fish_state = binaryHMM_test.generate_process()
plot_dynamics(belief, loc, act, measurement,
fish_state, binaryHMM_test.choose_policy)
plt.show()# @title Submit your feedback
content_review(f"{feedback_prefix}_Dynamics_with_different_thresholds_Interactive_Demo_and_Discussion")セクション 5: 価値関数の実装
# @title Video 5: Evaluate policy
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'aJhffROC74w'), ('Bilibili', 'BV1TD4y1D7K3')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Evaluate_policy_Video")コーディング演習 5.1: 価値関数の実装
閾値がどれほど良いかを調べましょう。そのために、効用(合計ポイント)を定量化する価値関数を計算します。この価値を使って異なる閾値を比較します。目標は、位置を変える努力を最小限にしつつ、釣れる魚の量を最大化することでした。
価値は単位時間あたりの期待効用の合計です。
ここで、 は位置 で得られる瞬間的報酬、 は選択した行動に対するコストです。魚を釣ると1ポイント得て、位置を変えると cost_sw ポイントのコストを支払います。
報酬と行動の確率に基づいて数学的に平均を取ることもできますが、長時間にわたる_実際の_報酬とコストの平均を取ることで同じ答えが得られます。これを行います。
指示:関数 get_value(rewards, actions, cost_sw) を完成させてください。
def get_value(rewards, actions, cost_sw):
"""
value function
Args:
rewards (numpy array of length T): whether a reward is obtained (1) or not (0) at each time step
actions (numpy array of length T): action, "stay" or "switch", taken at each time step.
cost_sw (float): the cost of switching to the other location
Returns:
value (float): expected utility per unit time
"""
actions_int = (actions == "switch").astype(int)
############################################################################
## 1. Modify the code below to compute the value function (equation V(theta))
##
## 2. After completing the function, comment this line:
raise NotImplementedError("Student exercise: Please complete the code")
############################################################################
# Calculate the value function
value = ...
return value
# Test your function
test_value_function()ご覧ください
よくできました!
# @title Submit your feedback
content_review(f"{feedback_prefix}_Implementing_a_value_function_Exercise")コーディング演習 5.2: ポリシーを実行する
しきい値の良さを判定する仕組みができたので、ブルートフォース法を使って最適なしきい値を計算しましょう。すべてのしきい値を試し、それぞれの価値をシミュレーションして、最も良いものを選びます。関数 get_optimal_threshold(p_stay, low_rew_p, high_rew_p, cost_sw) を完成させてください。関数の出力を可視化するコードは提供しています。このプロットでどのしきい値が最大の効用を持つか観察しましょう。
考える質問:
- 非常に高い切り替えコストを試してみてください。最適なしきい値は何ですか?それはどのように理解できますか?
- 切り替えコストがゼロの場合はどう違いますか?
- 一般的に、切り替えコストが変わると最適なしきい値はどのように変化しますか?
# Set a large time horizon to calculate meaningful statistics
large_time_horizon = 10000
get_randomness(large_time_horizon)
def run_policy(threshold, p_stay, low_rew_p, high_rew_p):
"""
This function executes the policy (fully parameterized by the threshold) and
returns two arrays:
The sequence of actions taken from time 0 to T
The sequence of rewards obtained from time 0 to T
"""
params = [p_stay, low_rew_p, high_rew_p, threshold]
binaryHMM_test = binaryHMM_belief(params, choose_policy="threshold", T=large_time_horizon)
_, _, actions, rewards, _ = binaryHMM_test.generate_process()
return actions, rewards
def get_optimal_threshold(p_stay, low_rew_p, high_rew_p, cost_sw):
"""
Args:
p_stay (float): probability of fish staying in their current location
low_rew_p (float): probability of catching fish when you and the fist are in different locations.
high_rew_p (float): probability of catching fish when you and the fist are in the same location.
cost_sw (float): the cost of switching to the other location
Returns:
value (float): expected utility per unit time
"""
############################################################################
## 1. Modify the code below to find the best threshold using brute force
##
## 2. After completing the function, comment this line:
raise NotImplementedError("Student exercise: Please complete the code")
############################################################################
# Create an array of 20 equally distanced candidate thresholds (min = 0., max=1.):
threshold_array = ...
# Using the function get_value() that you coded before and
# the function run_policy() that we provide, compute the value of your
# candidate thresholds:
# Create an array to store the value of each of your candidates:
value_array = ...
for i in ...:
actions, rewards = ...
value_array[i] = ...
# Return the array of candidate thresholds and their respective values
return threshold_array, value_array
# Feel free to change these parameters
stay_prob = .9 # Fish stay at current location with probability stay_prob
low_rew_prob = 0.1 # Even if fish are somewhere else, you can catch some fish with probability low_rew_prob
high_rew_prob = 0.7 # When you and the fish are in the same place, you can catch fish with probability high_rew_prob
cost_sw = .1 # When you switch locations, you pay this cost: cost_sw
# Visually determine the threshold that obtains the maximum utility.
# Remember, policies are parameterized by a threshold on beliefs:
# when your belief that the fish are on your current side falls below a threshold 𝜃, you switch to the other side.
threshold_array, value_array = get_optimal_threshold(stay_prob, low_rew_prob, high_rew_prob, cost_sw)
plot_value_threshold(threshold_array, value_array)出力例:
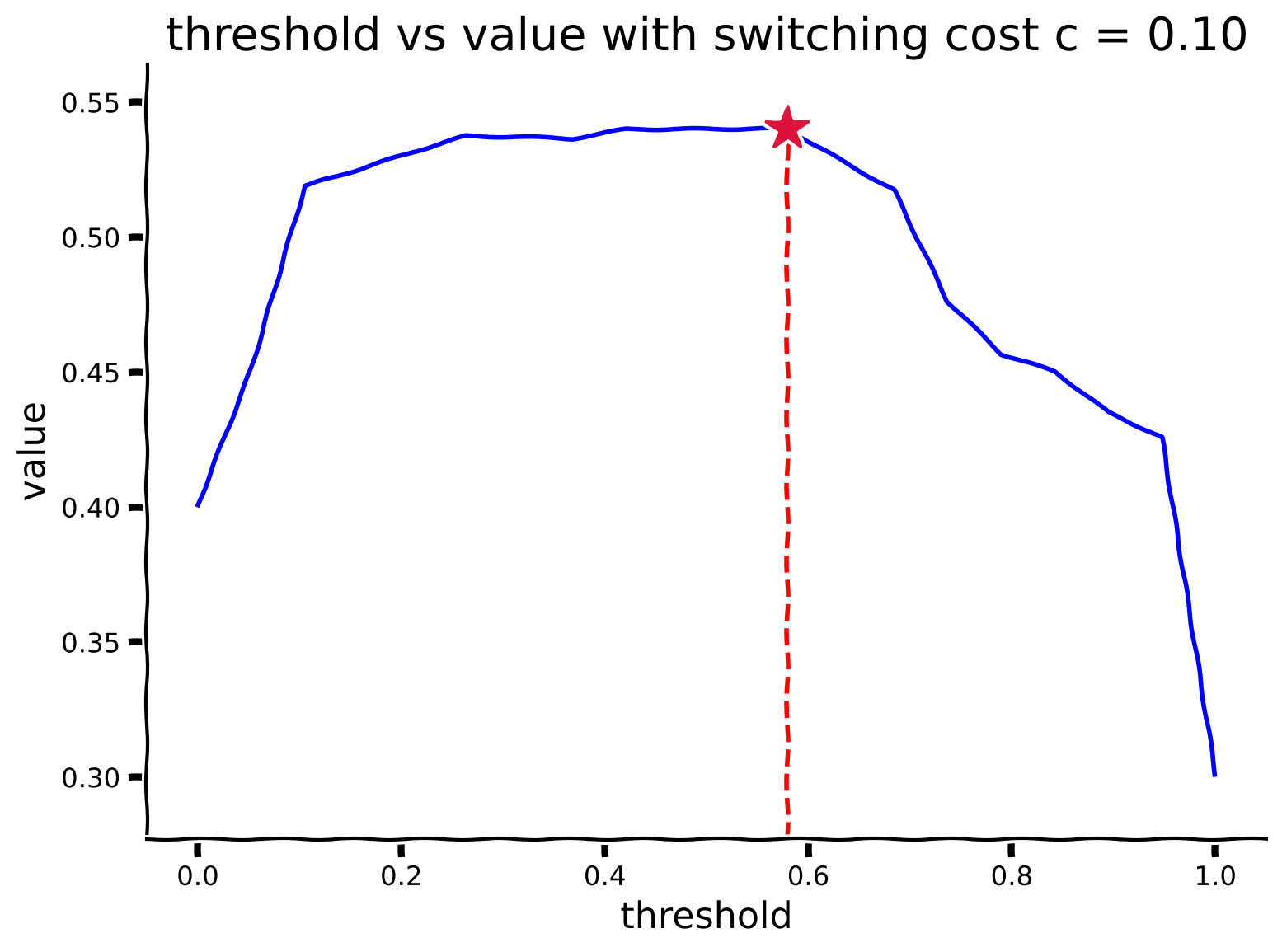
# @title Submit your feedback
content_review(f"{feedback_prefix}_Run_the_policy_Exercise_and_Discussion")まとめ
このチュートリアルでは、隠れマルコフモデルと行動を組み合わせて最適制御問題を解きました!これにより、部分観測マルコフ決定過程(POMDP)の基本的な形式が示されました。
観測(釣れた魚)を使って、魚の位置を推定するための信念(事後分布)を構築しました。次に、異なるポリシーの質を評価するための価値関数を計算しました。最後にブルートフォース法を用いて、場所の切り替えの労力を最小限に抑えつつ、できるだけ多くの魚を釣る最適なポリシーを発見しました。
次のチュートリアルでは、ここで使った二値の状態と行動の代わりに連続状態と連続行動を扱います。連続制御でもPOMDPを使うことはできますが、ポリシーが依然として示唆に富むため、完全に観測可能な場合の制御、すなわちマルコフ決定過程(MDP)に焦点を当てます。
# @title Video 6: From discrete to continuous control
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'ndCMgdjv9Gg'), ('Bilibili', 'BV1JA411v7jy')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_From_discrete_to_continuous_control_Video")ボーナス
ボーナスセクション 1: 最適ポリシーは課題にどう依存するか?
# @title Video 7: Sensitivity of optimal policy
from ipywidgets import widgets
from IPython.display import YouTubeVideo
from IPython.display import IFrame
from IPython.display import display
class PlayVideo(IFrame):
def __init__(self, id, source, page=1, width=400, height=300, **kwargs):
self.id = id
if source == 'Bilibili':
src = f'https://player.bilibili.com/player.html?bvid={id}&page={page}'
elif source == 'Osf':
src = f'https://mfr.ca-1.osf.io/render?url=https://osf.io/download/{id}/?direct%26mode=render'
super(PlayVideo, self).__init__(src, width, height, **kwargs)
def display_videos(video_ids, W=400, H=300, fs=1):
tab_contents = []
for i, video_id in enumerate(video_ids):
out = widgets.Output()
with out:
if video_ids[i][0] == 'Youtube':
video = YouTubeVideo(id=video_ids[i][1], width=W,
height=H, fs=fs, rel=0)
print(f'Video available at https://youtube.com/watch?v={video.id}')
else:
video = PlayVideo(id=video_ids[i][1], source=video_ids[i][0], width=W,
height=H, fs=fs, autoplay=False)
if video_ids[i][0] == 'Bilibili':
print(f'Video available at https://www.bilibili.com/video/{video.id}')
elif video_ids[i][0] == 'Osf':
print(f'Video available at https://osf.io/{video.id}')
display(video)
tab_contents.append(out)
return tab_contents
video_ids = [('Youtube', 'wd8IVsKoEfA'), ('Bilibili', 'BV1QK4y1e7N9')]
tab_contents = display_videos(video_ids, W=854, H=480)
tabs = widgets.Tab()
tabs.children = tab_contents
for i in range(len(tab_contents)):
tabs.set_title(i, video_ids[i][0])
display(tabs)# @title Submit your feedback
content_review(f"{feedback_prefix}_Sensitivity_of_optimal_policy_Bonus_Video")ボーナスインタラクティブデモ 1: 課題パラメータを探る
このデモでは、さまざまな課題パラメータを操作できます。以下を調整したときに最適なしきい値がどう変わるか観察してください:
- 切り替えコスト
- 魚の動態(
p(stay)) - それぞれの側で魚が釣れる確率、 と
これらのパラメータが変わると最適なしきい値がなぜ変わるのか説明できますか?
- 切り替えコストが低い/高い場合?
- 魚の動きが速い(すなわち低い
p_stay)場合? - 魚が釣れる確率が低い(すなわち低い と低い )場合?
異なるポリシーの価値の微妙な変化を見るには長いシミュレーションが必要な場合があるので、まずは大まかな傾向を探してください。
# @markdown Make sure you execute this cell to enable the widget!
display(HTML('''<style>.widget-label { min-width: 15ex !important; }</style>'''))
@widgets.interact(p_stay=widgets.FloatSlider(.95, description="p(stay)",
min=0., max=1.),
p_high_rwd=widgets.FloatSlider(.4, description="p(high_rwd)",
min=0., max=1.),
p_low_rwd=widgets.FloatSlider(.1, description="p(low_rwd)",
min=0., max=1.),
cost_sw=widgets.FloatSlider(.2, description="switching cost",
min=0., max=1., step=.01))
def update_ex_bonus(p_stay, p_high_rwd, p_low_rwd, cost_sw):
"""
p_stay: probability fish stay
high_rew_p: p(catch fish) when you're on their side
low_rew_p : p(catch fish) when you're on other side
cost_sw: switching cost
"""
# Set a large time horizon to calculate meaningful statistics
large_time_horizon = 10000
get_randomness(large_time_horizon)
threshold_array, value_array = get_optimal_threshold(p_stay,
p_low_rwd,
p_high_rwd,
cost_sw)
plot_value_threshold(threshold_array, value_array)# @title Submit your feedback
content_review(f"{feedback_prefix}_Explore_task_parameters_Bonus_Interactive_Demo_and_Discussion")